Go internal memory layout
2021-04-21
最近在研究 ebpf traceing golang 的函数入参和返回值,这个需要对程序的内存布局有比较熟悉的了解。 这篇文章就是研究过程中的一个记录
一个列子
package main
import (
"fmt"
"unsafe"
)
type T1 struct {
a int8
b int64
c int16
}
type T2 struct {
a int8
c int16
b int64
}
func main() {
fmt.Printf("int16 size: %d align: %d \n", unsafe.Sizeof(int16(0)), unsafe.Alignof(int16(0)))
fmt.Printf("int8 size: %d align: %d \n", unsafe.Sizeof(int8(0)), unsafe.Alignof(int8(0)))
fmt.Printf("int64 size: %d align: %d \n", unsafe.Sizeof(int64(0)), unsafe.Alignof(int64(0)))
t1 := T1{}
t2 := T2{}
fmt.Printf("t1 size: %d, align: %d\n", unsafe.Sizeof(t1), unsafe.Alignof(t1))
fmt.Printf("t2 size: %d, align: %d\n", unsafe.Sizeof(t2), unsafe.Alignof(t2))
}
在 mac 上运行程序的输出的结果为:
/private/var/folders/v0/rty_ljcj4_z7q15r0mc29hl80000gp/T/___go_build_memorylayout_go
int16 size: 2 align: 2
int8 size: 1 align: 1
int64 size: 8 align: 8
t1 size: 24, align: 8
t2 size: 16, align: 8
Process finished with exit code 0
从上面的输出可以看到,int16,int8,int64 的大小分别为,2,1,8 个字节,所以这个三个类型的结构体应该是 11 个字节。
但是实际上 T1,T2 对应的结构体大小分别为 24,16。
分析
为什么 T1 和 T2只是属性的顺序不一样,结构体的大小相差这么大呢?
为什么需要做内存对其
- 平台(移植性)原因:不是所有的硬件平台都能够访问任意地址上的任意数据。例如:特定的硬件平台只允许在特定地址获取特定类型的数据,否则会导致异常情况
- 性能原因:若访问未对齐的内存,将会导致 CPU 进行两次内存访问,并且要花费额外的时钟周期来处理对齐及运算。而本身就对齐的内存仅需要一次访问就可以完成读取动作
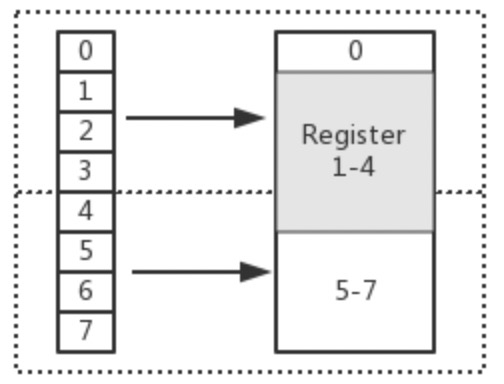
在上图中,假设从 Index 1 开始读取,将会出现很崩溃的问题。因为它的内存访问边界是不对齐的。 因此 CPU 会做一些额外的处理工作。如下:
- CPU 首次读取未对齐地址的第一个内存块,读取 0-3 字节。并移除不需要的字节 0
- CPU 再次读取未对齐地址的第二个内存块,读取 4-7 字节。并移除不需要的字节 5、6、7 字节
- 合并 1-4 字节的数据
- 合并后放入寄存器
从上述流程可得出,不做 “内存对齐” 是一件有点 “麻烦” 的事。因为它会增加许多耗费时间的动作
而假设做了内存对齐,从 Index 0 开始读取 4 个字节,只需要读取一次,
也不需要额外的运算。这显然高效很多,是标准的空间换时间做法。
内存对齐分析
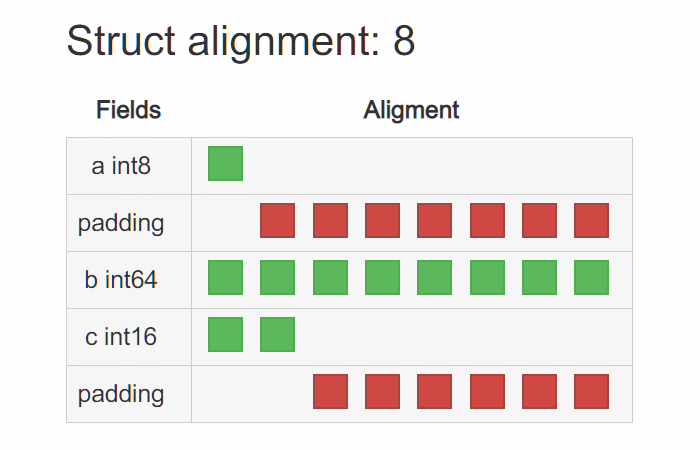
还是拿上面的 T1、T2 来说,在 x86_64 平台上,T1 的内存布局为:
T2 的内存布局为(int16 的对齐系数为 2):
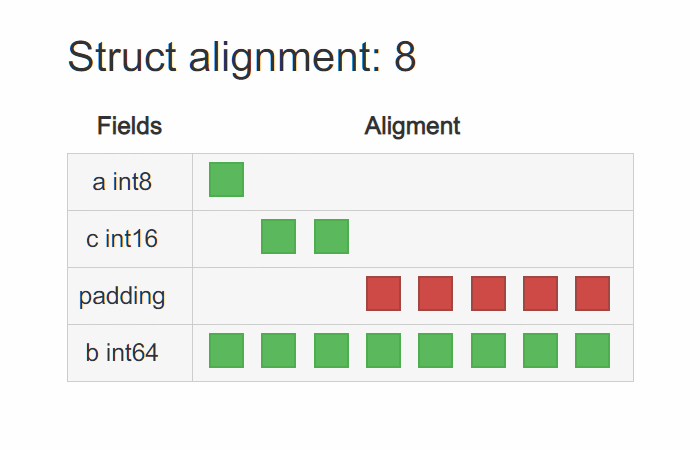
仔细看,T1 存在许多 padding,显然它占据了不少空间。 那么也就不难理解,为什么调整结构体内成员变量的字段顺序就能达到缩小结构体占用大小的疑问了, 是因为巧妙地减少了 padding 的存在。让它们更 “紧凑” 了。
另外一个列子
package main
import (
"sync/atomic"
)
type T3 struct {
b int64
c int32
d int64
}
func main() {
a := T3{}
atomic.AddInt64(&a.d, 1)
}
编译为 64bit 可执行文件,运行没有任何问题;但是当编译为 32bit 可执行文件,运行就会 panic:
$GOARCH=386 go build aligned.go
$
$ ./aligned
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x0 pc=0x8049f2c]
goroutine 1 [running]:
runtime/internal/atomic.Xadd64(0x941218c, 0x1, 0x0, 0x809a4c0, 0x944e070)
/usr/local/go/src/runtime/internal/atomic/asm_386.s:105 +0xc
main.main()
/root/gofourge/src/lab/archive/aligned.go:18 +0x42
原因就是 T3 在 32bit 平台上是 4 字节对齐,而在 64bit 平台上是 8 字节对齐。在 64bit 平台上其内存布局为:
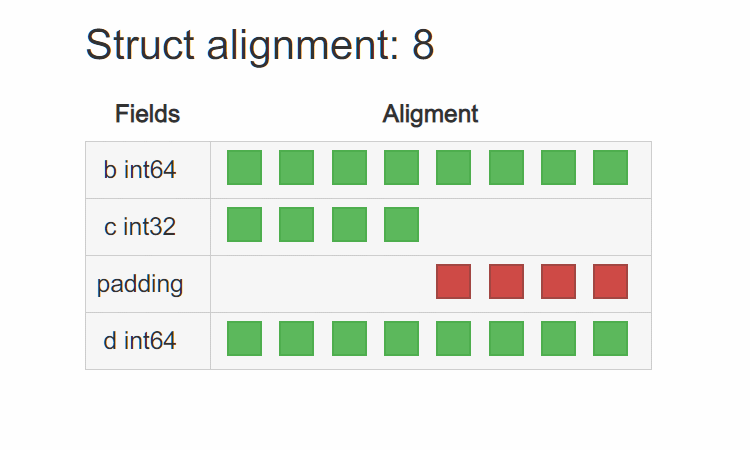
可以看到编译器为了让 d 8 字节对齐,在 c 后面 padding 了 4 个字节。而在 32bit 平台上其内存布局为:
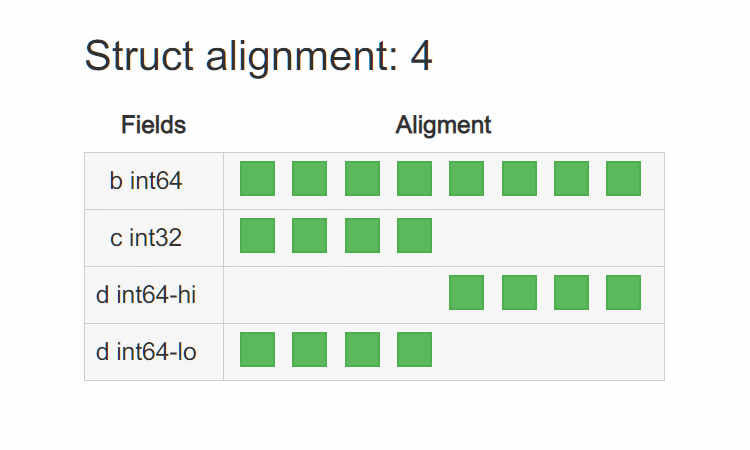
编译器用的是 4 字节对齐,所以 c 后面 4 个字节并没有 padding,而是直接排列 d 的高低位字节。
为了解决这种情况,我们必须手动 padding T3,让其 “看起来” 像是 8 字节对齐的:
type T3 struct {
b int64
c int32
_ int32
d int64
}
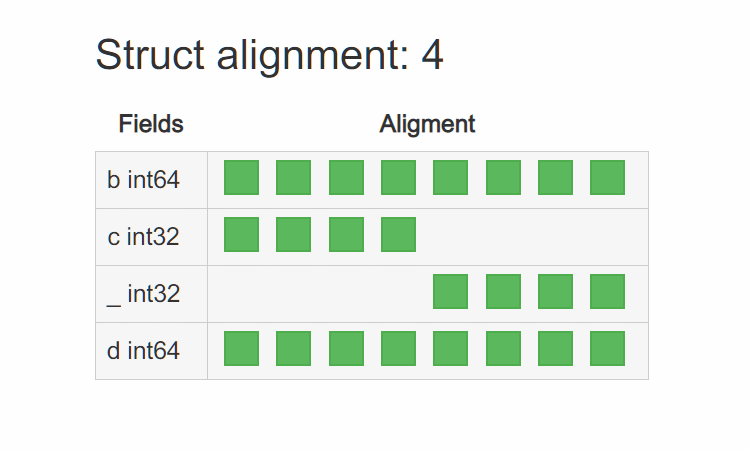
看起来就像 8 字节对齐了一样,这样就能完美兼容 32bit 平台了。 其实很多知名的项目,都是这么处理的,比如 groupcache:
type Group struct {
_ int32 // force Stats to be 8-byte aligned on 32-bit platforms
// Stats are statistics on the group.
Stats Stats
}
为什么需要了解这些
- 编写的代码在性能(CPU、Memory)方面有一定的要求
- ebpf trace golang 程序相关的工作
- 某些硬件平台(ARM)体系不支持未对齐的内存访问