Process scheduler
2021-05-14
Process lifetime
进程的生命周期如下图所示:
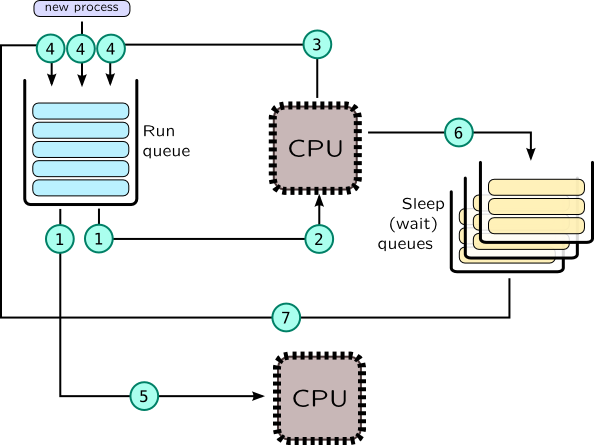
在调度器中,上下文切换分为以下两个步骤:
- 当前任务离开 CPU,以下是引起这个的原因:
- task 被 kernel 同步对象阻塞
(6),例如调用 poll() 等待网络数据。 在这种情况下,task 会被放置到同步对象的sleep queue中。 如果这个随后被其他 task 解除阻塞(7),这个会被移动到run-queue中。 - task 通过调用
yield()主动放弃 CPU 的控制(3)。 - task CPU 时间片到期,或者有更高优先级的 task 添加到 run queue 中,这个被叫做
抢占。(3)一些系统调用和中断也可以触发上下文切换。
- task 被 kernel 同步对象阻塞
- 新的 task 被挑选到 CPU 上运行
(2)。
在 SMP 系统中,操作系统至少会为每个 CPU 创建一个 run-queue。 当一些 CPU 空闲时,这个会检查其他 CPU 的 run-queues 并且 steal task, 因此 task 会在 CPU 间迁移(5)。这个能平衡不同 CPU 间的 task, 但是其他因素也是需要考量的,如 NUMA 进程内存的局部性,缓存热度等。
如前所述,调度器的主要目标是分配 task 的执行时间。为了做到这个, 为了 task 的优先,所以会创建多个 queues 选择一个 task 来执行(每一个优先级一个队列)。 而不是遍历所有的队列选择高优先级的 task 执行。这种方式被叫做 cyclic planning。 Fair planning,会考虑不同的线程,进程,用户,服务,尝试平衡处理器上的运行时间。
通常 task 会阻塞在各种同步对象上等待可用数据,例如 accept() 会一直阻塞直到 client 端 connect,
recv() 将一直阻塞直到 client 端发送新的数据。当前没有可用数据时是不需要 CPU 的,
所以 task 简单的放弃 CPU,并且放置到相关对象特定的 sleep queue 中。
也就是说 accept() 调用,linux kernel socket 对象的 sk_wq 等待队列上。
Scheduling in Linux
让我们来看看 CFS 调度器的实现细节。
首先,调度器不会直接处理 task,调度器以 struct sched_entity 为调度单元。
调度单元可以代表一个 task,或者一组以队列存在的 task,数据结构为 struct cfs_rq(通过属性 my_q 引用),
所有允许构建有层级的调度单元,分配资源给一组 task 这种技术叫做 CGroups。
struct rq 中的属性 cfs 这个是 struct cfs_rq 的一个实例,包含了所有高优先级的调度单元,这个是处理器的运行队列。
每一个调度单元有一个 cfs_rq 指针,这个指向 CFS 的运行队列:
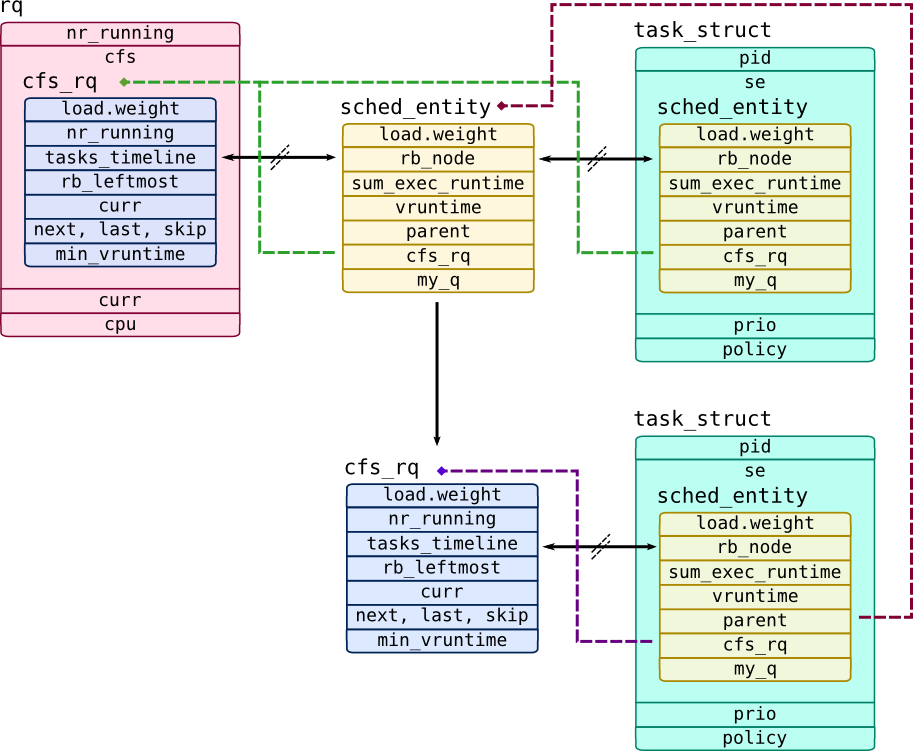
我们举例来说明,运行队列有两个调度单元: 一个是 CFS 队列包含单个 task(这个通过父指针引用 cfs_rq),一个是 top-level 基本的 task。
CFS 不会像 Solaris 系统中的 TS 调度器一样分配时间片。
使用 task 在 CPU 上的总运行时间来代替,这个时间保存在 sum_exec_runtime 属性上。
当调度 task 调度到 CPU 上时,sum_exec_runtime 会保存到 prev_sum_exec_runtime 上,
所以计算这个两个属性的差值,就能直到这个 task 在 CPU 上的运行时间。
sum_exec_runtime 的计时单位是纳秒,但是这个不会直接用来度量 task 的运行时间。
为了实现抢占式,CFS 使用运行时长除以 task 权重(属性 load.weight),
所以更高权重的 task 将会有更低的度量(保存在 vruntime 属性中)。
根据 task 的 vruntime 排序在红黑树中,这个红黑树被叫做 tasks_timeline,
所有最左边的 task 有最低的 vruntime,这个保存在红黑树的 rb_leftmost。
CFS 对于已经被换醒的 task 存在特殊的例子。 因为这个 task 已经 sleep 太久,所以它们的 vruntime 可能会太低,它们会存在不公平的 CPU 时间。 为了防止这种情况,CFS 会保留一个最小的 vruntime 在 task 属性 min_vruntime 中, 所有唤醒的 task 将使用 min_vruntime 减去预计的 timeslice 值。 CFS 有个伙伴系统,帮助调度程序指向:
- 下一个最近唤醒的 task
- 最后一个被驱逐的并且跳过通过调用 sched_yield() 的 task