Evaluated JSON Encoding and Compression Algorithms
2016-03-01
这篇文章是上面的系列中提到的 JSON blob 中数据的编码和压缩方面的文章。
Imagine you have to store data whose massive influx increases by the hour. Your first priority, after making sure you can easily add storage capacity, is to try and reduce the data’s footprint to save space. But how? This is the story of Uber Engineering’s comprehensive encoding protocol and compression algorithm test and how this discipline saved space in our Schemaless datastores.
我们想象这样一种场景,短时间内数据存储怎么保存大量的数据。我们的第一原则是,确保我们可以非常容易的添加存储空间,还是试着尝试减少数据的空间? 这篇文章将尝试讲述 uber 工程师在选择编码协议和压塑算法所做的工作。
As of early 2016, many millions of trips flow through Uber’s platform every day across 400+ cities in over 60 countries on 6 continents. Between services, trip data is often passed around as JSON blobs, which typically take up 20 kilobytes (KB) a piece. Eventually, trip data is stored in Mezzanine, Uber’s Schemaless-backed datastore, for further processing, billing, and analytics. Schemaless is inherently append-only storage, so data piles up.
早在 2016 之前,uber 的数据量就已每天数百万计数量级增加,这个包括了 6 大洲,60 多个国家的 400 多个城市。 在各个服务之间,我们的核心数据 trip 是以 JSON blobs 来传递的,它一般情况下是以 20KB 大小。最后,trip data 是存储在 uber 的后端存储系统 Mezzanine 中的, 这个会被后来的 账单,分析服务处理。schemaless 系统内部是追加模式的,所以数据是堆叠的。
Let’s do the math: each million trips at 20 KB yields 20 gigabytes (GB) of trip data per day. Schemaless stores its data across many physical hosts. If Uber were not a hypergrowth company and trip growth instead expanded linearly, a single disk of 1 terabyte (TB) would last just 51 days. Subtract from that ~40% of space used by system components, and you’re down to 30 days per host. Thus an installation of 32 TB lasts < 3 years for 1 million trips, < 1 year for 3 million trips, and < 4 months for 10 million trips—that is, if you store raw JSON.
我们来做一道数学题:每天增加百万的数据,每条数据是 20KB 的大小,这就意味着每天有 20GB 的数据要存储。schemaless 系统的数据存储是跨越多个物理机器的。 如果 uber 不是一家高速发展的企业,trip 的增长不是线性可宽展的,单个 1 TB 的磁盘仅仅只能存储 51 天的数据。扣除点 40% 的空间用于系统存储,我们每台物理机器只能够存储 30 的数据。 因此一个 32GB 的存储只能存储最经 3 年的数据,最近 1 的数据有 3 百万条,最近 4 个月的数据 1000W 条。
Since JSON data lends itself very well to compression, we were convinced we could find an algorithm that could squeeze the data without sacrificing performance. Reclaiming several KB per trip across hundreds of millions of trips during the year would save us lots of space and give us room to grow.
因为 JSON 数据有着很好的压缩性,所以我们确信我们能够找到一种算法不损失性能的压缩算法。在数以亿级的数据上节省几 KB 的数据,就能是的我们有大量的空间来维持增长。
A Matter of Protocol
JSON bridges the gap between human readable and machine parsable via a more compact syntax than SGML and XML, but it is still ultimately ASCII. The first natural step when optimizing for space is to use a binary encoding instead, and then put a compression algorithm on top.
JSON 相比起 SGML 和 XML 是在可读性和机器可解析性之间的一个平衡。但是这个最总还是还是一个 ASCII 字符。很自然的,我们第一步就是需要使用二进制编码来优化空间, 这是在顶层可以使用压缩算法。
Encoding protocols fall into two major categories: protocols using an IDL and those that don’t. IDL-based encodings require schema definitions. They offer peace of mind with respect to data format and validation for consumers while sacrificing flexibility in the schema’s evolution. Non-IDL-based encodings are typically generic object serialization specifications, which define a compact format on top of a fixed type system. They provide a flexible serialization mechanism but only give basic validation on types. We evaluated three IDL based encoding protocols and seven non-IDL based encodings:
编码协议主要在两个领域:协议是否需要使用 IDL(Interface description language)。IDL-based 的编码是需要 schema 预定义的。 这种模式下提供了数据格式校验但是牺牲了灵活性。非 IDL-based 编码一般情况下是一种特定的对象序列化,它定义了一种紧凑的固定格式系统。它提供一种灵猴的序列化机制, 但是只有基本的数据校验。我们评估了 3 中 IDL 编码协议和 7 中非 IDL 编码协议:
| Encoding Protocol | Schema-based (IDL) | |
|---|---|---|
| 1 | Thrift | Yes |
| 2 | Protocol Buffers | Yes |
| 3 | Avro | Yes |
| 4 | JSON | No |
| 5 | UJSON | No |
| 6 | CBOR | No |
| 7 | BSON | No |
| 8 | MessagePack | No |
| 9 | Marshal | No |
| 10 | Pickle¹ | No |
For compression, we put three lossless and widely accepted libraries to the test:
对于压缩方面,我们评估 3 中无损和广泛使用的库:
- Snappy
- zlib
- Bzip2 (BZ2)
Snappy aims to provide high speeds and reasonable compression. BZ2 trades speed for better compression, and zlib falls somewhere between them.
Snappy 关注的压缩速度方面和可靠的压缩。BZ2 是提供压缩速度和更好的压缩率,zlib 则是处理这两种方案之间。
Testing
Our goal was to find the combination of encoding protocol and compression algorithm with the most compact result at the highest speed. We tested encoding protocol and compression algorithm combinations on 2,219 pseudorandom anonymized trips from Uber New York City (put in a text file as JSON). We wrote a test script in Python to benchmark each option (IDL files were handcrafted from trip JSON data for Thrift, Protocol Buffers, and Avro). Then, the script was put to work. Looping through all, the script measured time spent encoding/decoding, compressing/inflating, and the gain or loss in size. Here it is in pseudocode:
我们的目的就是要找出编码协议和压缩算法联合后,哪一个有着更高的压缩率和速度。我们测试了 uber 中纽约这个城市中的 2219 伪随机匿名 trip 数据。 我们使用 Python 写了一个测试脚本来测试每一个方案(IDL 是手工处理的)。我们循环测试这个压缩使用的时间和压缩率,下面是伪代码:
foreach (encode/decode, compress/decompress):
start = time.now()
packed = encode(compress(json))
size = len(packed)
unpack = decode(decompress(packed))
elapsed = time.now() - start
Comparing Results by Size and Speed
The following graphs show the results:
下图展示了这个结果:
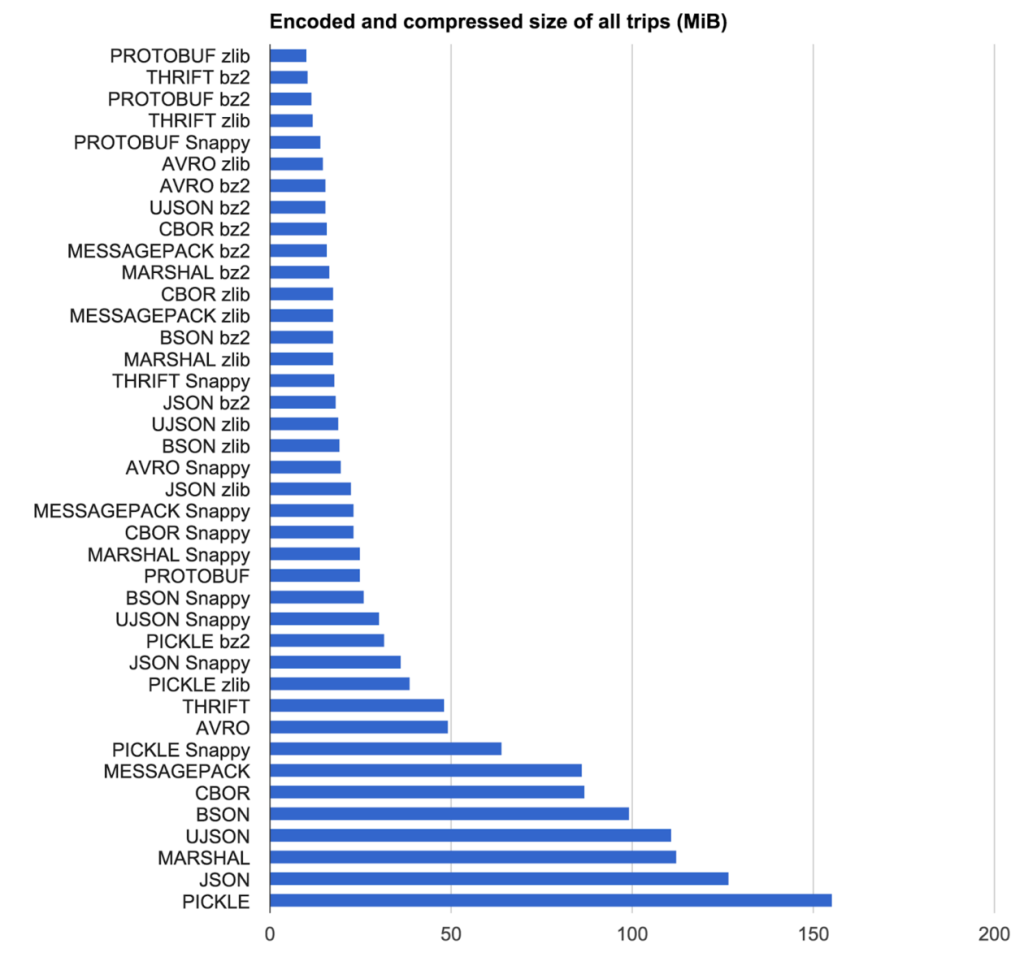
For size, the combination Protocol Buffers (PROTOBUF) compressed with zlib was just slightly better than Thrift with BZ2, squeezing data to just above 8% of its uncompressed JSON equivalent. Disturbingly, storing pickled data was worse than just persisting raw JSON.
压缩率方面,Protocol Buffers 和 zlib 的组合仅仅略好于 Thrift 和 BZ2 组合,序列化数据比没有压缩的 JSON 数据量略高 8%。 遗憾的是,存储方面这个数据仅仅好于原生的 JSON。
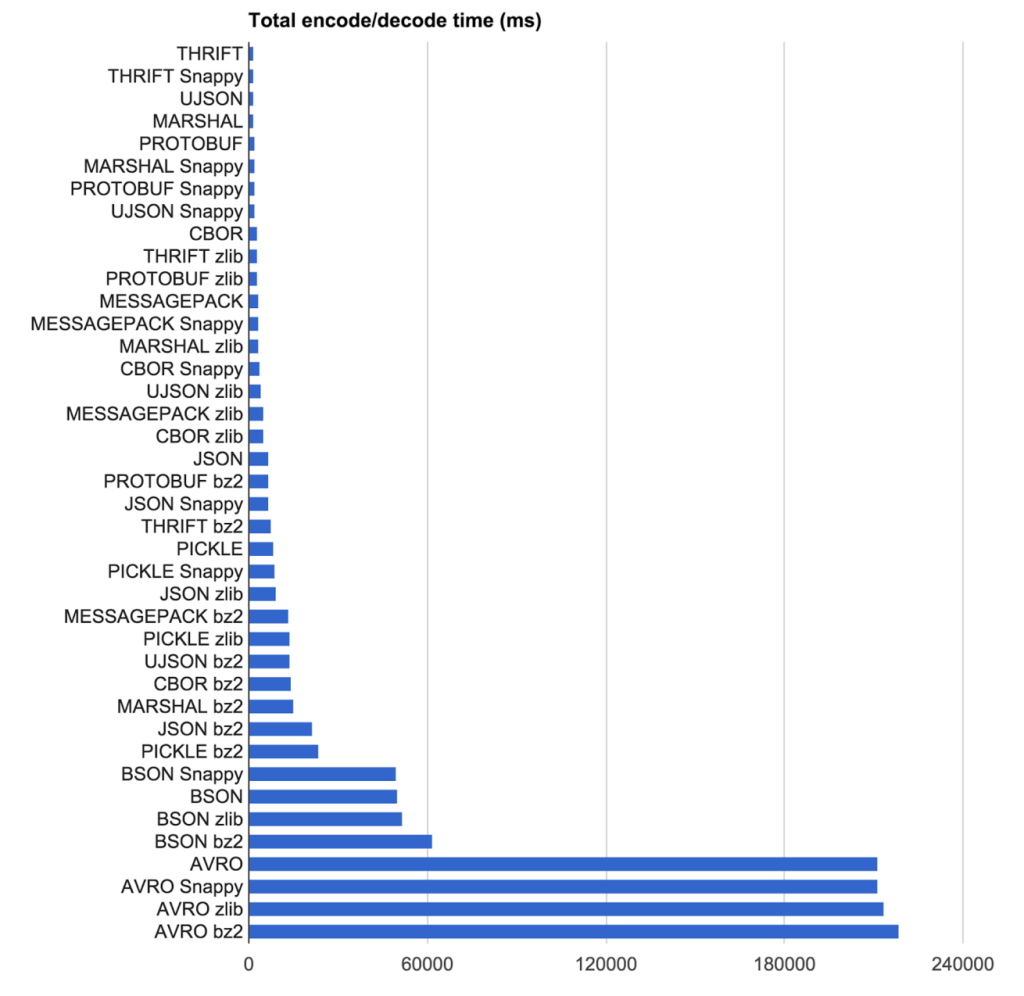
For speed, Thrift won the race by spending only 1548 ms: 23% of the 6535 ms it takes to use JSON with the native C++ backed implementation, and vice versa. The native Python Avro implementation, on the other hand, ran at 211,540 ms: more than 32 times slower than the native JSON encoder. There is a fastavro implementation, which claims to be an order of magnitude better, but it is not feature complete and thus wasn’t tested.
速度方面,Thrift
The Verdict
The tradeoffs of each encoding and compressing option can be evaluated against each other in a scatter diagram. The pareto front, shown as a red line on the graph, potentially gives us the most optimal solutions:
权衡每一种编码和压缩方案我们可以得到下面的图表。这个图的前面,红色线部分,可能给我指定一个最优的解决方案:
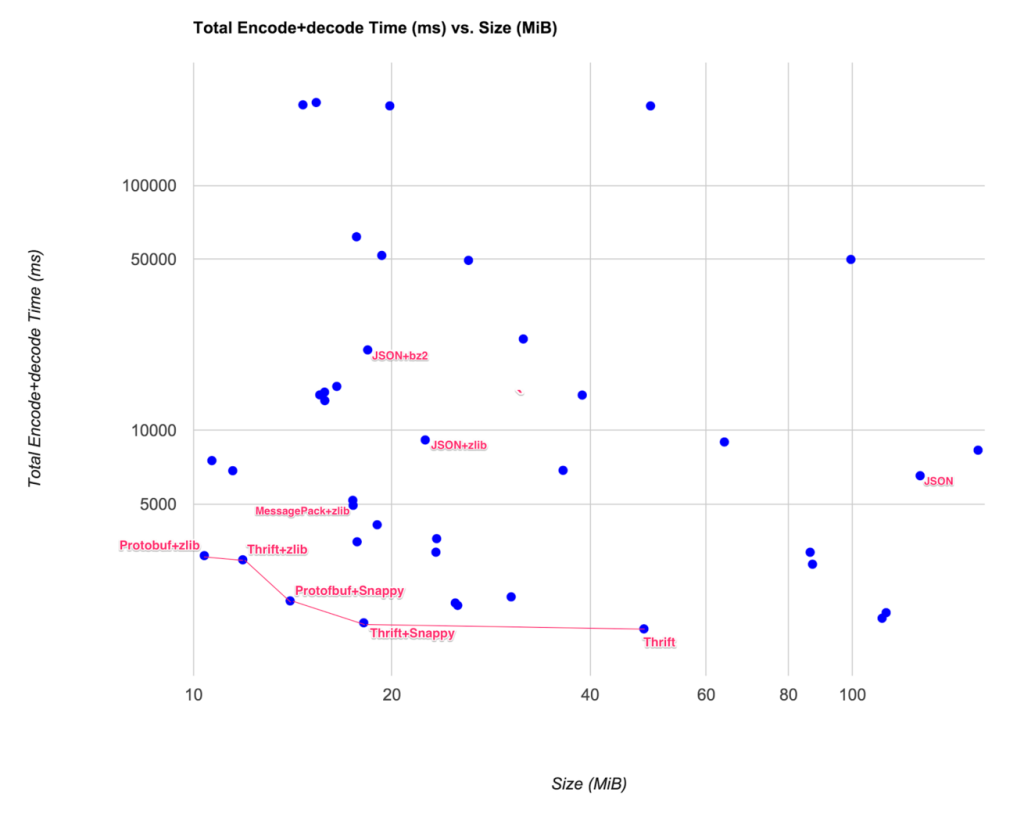
Essentially, the bottom left corner is what we were aiming for: small size and a short time to encode and decode.
本质上,图表的走下方,表明了:更小的压缩和更少的压缩时间。
Key conclusions:
关键性结论:
- Simply compressing JSON with zlib would yield a reasonable tradeoff in size and speed. The result would be just a little bigger, but execution was much faster than using BZ2 on JSON.
- Going with IDL-based protocols, Thrift and Protocol Buffers compressed with zlib or Snappy would give us the best gain in size and/or speed.
- 简单的使用 zlib 压缩 JSON 是一个在速度和大小方面很好的权衡。 这个结果仅仅是一个更好的方案,但是使用 BZ2 压缩 JSON 有着更好的速度。
- 使用 IDL-based 协议,Thrift 和 Protocol Buffers 结合 zlib 或者 Snappy 能够给我们更好的速度和压缩率。
Since JSON compressed with zlib was in fact a good candidate, we decided to measure up the remaining contenders against that baseline. So we immediately ruled out any option that fell below JSON/zlib in either speed or size. We were left with the following shortlist:
因为 JSON 结合 zlib 是一个很好的候选方案,我们决定测试了其他的候选方案的对比基线。所以我们可以快速的排除掉其他的方案。下面的表格是一个测试列表:
| Encoder | Encode (ms) | Decode (ms) | Size (bytes) | Size Factor | Speed Factor |
|---|---|---|---|---|---|
| PROTOBUF zlib | 2158 | 925 | 10,885,018 | 46% | 34% |
| THRIFT bz2 | 5531 | 2003 | 11,178,018 | 47% | 82% |
| PROTOBUF bz2 | 5111 | 1738 | 12,023,408 | 51% | 75% |
| THRIFT zlib | 1817 | 1147 | 12,451,285 | 53% | 32% |
| PROTOBUF Snappy | 1224 | 790 | 14,694,130 | 62% | 22% |
| CBOR zlib | 2573 | 2611 | 18,290,630 | 78% | 57% |
| MESSAGEPACK zlib | 4231 | 715 | 18,312,106 | 78% | 54% |
| MARSHAL zlib | 2095 | 1416 | 18,567,296 | 79% | 38% |
| THRIFT Snappy | 628 | 1011 | 19,003,267 | 81% | 18% |
| UJSON zlib | 2956 | 1165 | 19,917,716 | 85% | 45% |
| JSON zlib | 5561 | 3586 | 23,560,699 | 100% | 100% |
Prior to Fall 2014, JSON structures passed between Uber’s services were not under strict schema enforcement. Using an IDL-based encoding protocol would require us to define IDL schemas and enforce them in Schemaless. This reduced the original list to the following contenders:
早在 2014,JSON 数据结构就成为 uber’s 众多服务中的通信格式,这个不会要求严格的 schema。使用 IDL-based 编码协议将要求我们定义 IDL schemas 在 schemless 中。 这样的情况下,我们可以将上面的列表简化:
| Encoder | Encode (ms) | Decode (ms) | Size (bytes) | Size Factor | Speed Factor |
|---|---|---|---|---|---|
| MESSAGEPACK zlib | 4231 | 715 | 18,312,106 | 78% | 54% |
| CBOR zlib | 2573 | 2611 | 18,290,630 | 78% | 57% |
| MARSHAL zlib | 2095 | 1416 | 18,567,296 | 79% | 38% |
| UJSON zlib | 2956 | 1165 | 19,917,716 | 85% | 45% |
| JSON zlib | 5561 | 3586 | 23,560,699 | 100% | 100% |
Marshal, being Python only, was out by default. JSON with zlib was bigger and slower than the rest of the pack, and while that left UJSON as the fastest candidate, the size was still a bit larger than CBOR and MessagePack. The final round of evaluation was between MessagePack and CBOR. CBOR proved to be slower, so when the scripts and judging ended, MessagePack with zlib was left standing.
编解码我们仅仅使用的 Python。JSON 和 zlib 的组合是一个很大数据包和更慢的,这个和 UJSON 候选方案相比,压速率方面是 CBOR 和 MessagePack 更好。 最后我们可以在 CBOR 和 MessagePack 之间候选。相比起来 CBOR 在速度方面更慢,所以 MessagePack 结合 zlib 笑到最后。
MessagePack/zlib is a much better choice than using the Python JSON encoder with no compression. While encoding is slower, decoding is much faster, and the relative size is an order of magnitude better:
MessagePack/zlib 方案在使用 JSON 而没有压缩时是更好的选择。这个是编码更慢,但是解码更快,这个相对关系压缩率方面是更好的:
| Encoder | Encode (ms) | Decode (ms) | Size (bytes) | Size Factor | Speed Factor |
|---|---|---|---|---|---|
| JSON | 3260 | 3275 | 132,852,837 | 564% | 71% |
| MESSAGEPACK zlib | 4231 | 715 | 18,312,106 | 78% | 54% |
What We Learned
There is a plethora of encoding protocols out there, and plentiful compression algorithms as well. We settled on MessagePack with zlib. We felt this was the best choice for our Python-based, sharded datastore with no strict schema enforcement (Schemaless). We only discovered this combination because we took a disciplined approach to test a wide range of protocols and algorithm combinations on real data and production hardware. First lesson learned: when in doubt, invest in benchmarking.
在这么多的编码协议和压缩算法中,我们选择了 MessagePack 和 zlib 的组合。我们觉得在 Python 方面这是一个最好的方案,共享存储在没有严格 schema 的情况下。 我们使用严谨的方式选择了这个方案,这个是基于广泛的协议和压缩算法组合测试的情况下的选择。 第一个教训:当我们有问题,应该采用基准测试来对比。
How much did we save in this instance? Let’s do the math again, this time reducing 20 KB by 86% to get 2,822 bytes, the size gain yielded by MessagePack+zlib over raw JSON. Multiply by a million trips and the storage space only increases by just under 3 GB, compared to 20 GB without compression. A 1 TB disk will now last almost a year (347 days), compared to a month (30 days) without compression. Assuming a Schemaless installation with 32 TB capacity and linear growth, we now have enough space to last over 30 years compared to just under 1 year, thanks to putting the squeeze on the data.
Encoding and compressing data is a smart move, and like a three star Michelin restaurant, it’s worth the journey to get there. Not only does it save space; it also significantly reduces the amount of time spent processing data. In everyday operations, this translates directly to hardware, which does not have to be bought, provisioned, and configured.