Uber's Schemaless Datastore part two
2016-02-25
第一部分介绍系统的设计,这部分主要讲解架构。
In Project Mezzanine: The Great Migration at Uber, we described how we migrated Uber’s core trips data from a single Postgres instance to Schemaless, our scalable and highly available datastore. Then we gave an overview of Schemaless—its development decision process, the overall data model—and introduced features like Schemaless triggers and indexes. This article covers Schemaless’s architecture.
Mezzanine 项目是 uber 的一个伟大的迁移,我们描述了如何将 uber 的核心数据 trip 从单个 Postgres 实例中迁移到高可用,可扩展的 schemaless 存储中。 随后我们看了 schemaless 系统的设计和开发过程,我们介绍了一些特性,像 触发器,索引。这篇文章我们看砍 schemaless 的架构。
Schemaless Synopsis
To recap, Schemaless is a scalable and fault-tolerant datastore. The basic entity of data is called a cell. It is immutable, and once written, it cannot be overwritten. (In special cases, we can delete old records.) A cell is referenced by a row key, column name, and ref key. A cell’s contents are updated by writing a new version with a higher ref key but same row key and column name. Schemaless does not enforce any schema on the data stored within it; hence the name. From Schemaless’s point of view, it just stores JSON objects. Schemaless uniquely supports efficient, eventually consistent secondary indexes over the cells’ fields.
回顾一下,schemaless 系统是一个可容错,可扩展的存储系统。最基本的存储单元叫做 cell。它具有不可变,只能写一次的,不能覆盖的特点。(在某些特殊的情况下,我们可以删除老的记录) 一个 cell 通过 row key,columns name,和 ref key 来唯一标识。cell 中的数据通过写入一个高版本的数据来达到更新的目的。schemaless 不强制任何存储 schema。 从 schemaless 的角度看,这些数据就是一个 JSON 对象。schemaless 支持高效的,唯一性的,最终一致性的索引。
Architecture
Schemaless has two types of nodes: worker nodes and storage nodes, located either on the same physical/virtual host or on separate hosts. Worker nodes receive client-side requests, fan out the requests to the storage nodes, and aggregate the results. The storage nodes contain data in such a way that single or multiple cell retrieval on the same storage node is fast. We separate the two node types to scale each part independently. An overview of Schemaless is shown below:
schemaless 由两种类型的 nodes 构成:worker node,和 storage nodes,它们可以处以同一个物理或者虚拟机中,也可以处于不同的物理或者虚拟机中。 worker nodes 接受 client 端的请求,根据请求找到 storage nodes,并且聚合结果。storage nodes 包含数据的方式查找单个或多个 cell 在同一存储节点非常快。 我们将这两种 node 解耦,如下图所示:
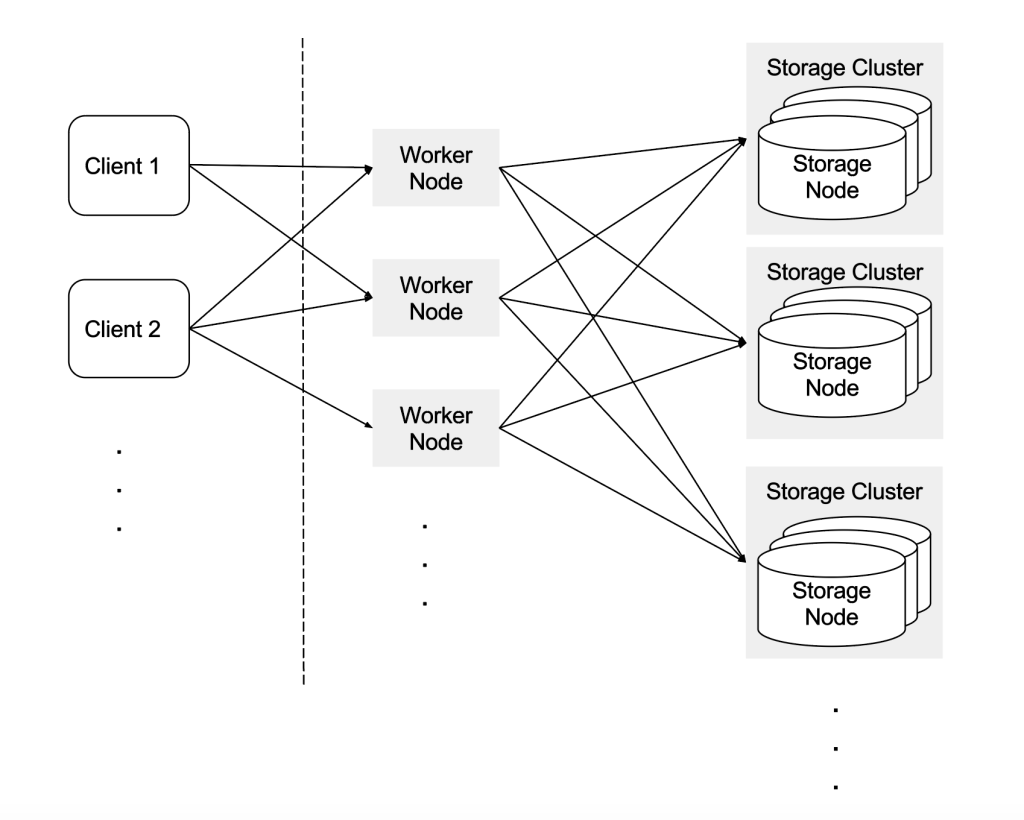
Worker Nodes
Schemaless clients communicate with the worker nodes via HTTP endpoints. These route requests to the storage nodes, aggregate the results from storage nodes if needed, and handle background jobs. In order to handle slow or failing worker nodes, a client-side library will transparently try other hosts and retry failing requests. Write requests to Schemaless are idempotent, so every request is safe to retry (a really nice property to have). This feature is exploited by the client library.
schemaless 系统的和 client 通信使用的 http 协议。worker 节点会路由请求到 storage nodes 上,聚合结果,和处理后台任务。 为了处理慢或者失败的请求,client 端会透明的重试到其他主机上。写请求是幂等的,所以每一个请求是安全的对于重试来说。这个特性是通过 client 的开发库来实现的。
Storage Nodes
We divide the data set into a fixed number of shards (typically configured to 4096), which we then map to storage nodes. A cell is mapped to a shard based on the row key of the cell. Each shard is replicated to a configurable number of storage nodes. Collectively, these storage nodes form a storage cluster, each consisting of one master and two minions. Minions (also known as replicas) are distributed across multiple data centers to provide data redundancy in case of a catastrophic data center outage.
我们将数据集合切割为固定数目的切片(一般配置为 4096),我们映射这些存储节点。单个 cell 的映射是通过 row key 来进行的。 每一个切片会配置一些复制集节点。这些集群中的切片节点统一配置为一个 master,2 个 minions 节点。minions 是分布在不同数据中心的,这样可以提供冗余和灾备的功能。
Read and Write Requests
When Schemaless serves a read request, such as reading a cell or querying an index, worker nodes can read the data from any storage node in its cluster. Reading from the master’s or minion’s storage nodes is configurable on a per request basis; the default is to read from the master, which means the client is guaranteed to see the result of its write request. Write requests (requests that insert cells), must go to the master of the cells’ cluster. After updating the master’s data, the storage node replicates the update asynchronously to the cluster’s minions.
当 schemaless 处理 read 请求时,例如读取一个 cell 或者查询一个索引,worker 节点可以中任何一个主节点或者从节点中进行,这个是可配置的。 默认配置是从 master 节点中读取,这样可以保证当 client 写入数据时,client 一定能读取到数据。 写请求必须在 master 节点上。当 master 节点上的数据发生变化时,storage 节点会异步的复制数据到 minions 节点上。
Dealing with Failure
An interesting aspect of distributed datastore systems is how they deal with failure, such as a storage node failing to respond to requests (master or minion). Schemaless is designed to minimize the impact of read and write request failures of storage nodes.
分布式系统中有趣的一方面就是:如何处理失败?例如当 storage 节点不能响应一个请求时(包括 master 和 minion)。 schemaless 被设计为了最小化读或者写失败的影响。
Read Requests
The setup of masters and minions implies that it can serve read requests as long as one node in a cluster is available. If the master is available, Schemaless can always return the latest data by querying it. If the master is unavailable, some data might not have propagated to the minion, so Schemaless may return stale data. In production, however, we typically see subsecond latency on the replication, so minions’ data tends to be fresh. Worker nodes use the circuit breaker pattern on storage node connections to detect when a storage node is in trouble. This way, reads failover to another node.
master 和 minions 的设计以为这集群中只要有一台机器可用,那么读取就不会失败。如果 master 可用那么 schemaless 系统将总是返回最新的数据。 如果 master 不可用,一些数据可能还没有复制到 minions 中,所以可能会返回过期的数据。在生成系统中,我们的复制延迟一般是秒级的,所以 minions 中的数据可以说是最新的。 当 storage 节点发生故障时,worker 节点会熔断。这是,读回路由到其他节点。
Write Requests
A minion going down does not impact writes; they go to the master. But if the master is down, Schemaless still accepts write requests, but they’re persisted to disk on another (randomly chosen) master. This is similar to hinted handoff in systems such as Dynamo or Cassandra. Writing to another master means that subsequent read requests cannot read these writes before the master is up or if a minion is promoted. In fact, Schemaless always writes to other masters to handle the failures in the asynchronous replication; we call this technique buffered writes (described in the next section).
当 minions 宕机时是不会影响写操作的,应为写会路由到 master 节点上。但是 master 节点宕机时,schemaless 系统任然是可以接受写操作的,但是是随机选择一个 master。 这个机制和 Dynamo, Cassandra 很相似。写入到其他的 master,意味着宕机的 master 没有恢复或者 minions 没有升级为 master 时是无法读取到数据的。 实际上,schemaless 总是写入数据到其他的 master 节点来应对这种失败,我们将这样的机制成为 buffered writes(这个随后描述)。
Using a single node for receiving writes yields a number of advantages and disadvantages. One advantage is that it gives a total order on writes to each shard. This is an important property for Schemaless triggers, our asynchronous processing framework (mentioned in the first Schemaless article), as it can read data for a shard from any node and still guarantee the same processing order. The cell write order is the same on all nodes in the cluster. So in some sense, Schemaless’s shards can be viewed as a partitioned cell revisions log.
使用单节点来接受写操作,存在着一些优点和缺点。一个优点就是这样就是全局有序的。这是一个非常好的特性对于触发器来说,异步处理框架就可以在随后读取到数据并且可以保证随后的处理流程。 cell 的写顺序在同一一个几点中都是一样的。从某种意义上来说,这样可以看做 schemaless cell 的一个的分区日志。
The most prominent disadvantage with a single master is if the master in a cluster is down, we buffer the writes somewhere else where they cannot be read. The upside to this inconvenient situation is that Schemaless can tell the client if the master is down, so the client will know that the written cell is not immediately reads-available.
这个中突出的缺点就是单个 master 节点宕机时,我们的 buffer writes 这个时候还不能读取。这样的情况下我们可以告知 client 端,现在写入的数据是能够马上读取到的。
Buffered Writes
Since Schemaless uses MySQL asynchronous replication, the write will be lost if a master receives a write request, persists the request, and then fails before it has replicated the write to the minions (e.g., in a hard drive failure). To solve this problem we use a technique called buffered writes. Buffered writes minimize the chance of losing data by writing it to multiple clusters. If a master is down, the data is not readily available for subsequent reads but has nevertheless been persisted.
因为 schemaless 使用 Mysql 的异步复制,写操作可能会丢失,当接受 master 写请求时,会一直失败,当 minions 发生故障时(例如:硬件故障)。 为了解决这个问题我们使用一种我们称之为 buffered writes 的技术。buffered writes 最小化了数据的丢失问题在集群中的发生。 当 master 宕机时,数据是不能立即读取到的在随后的请求中,但是这个不会是永久的,只要修复 master 的宕机即可。
With buffered writes, when a worker node receives a write request, it writes the request to two clusters: a secondary and a primary (in that order). The client is told that the write succeeded only if both succeed. See the diagram below:
在 buffered writes 中,当 worker 几点收到一个写请求时,这个写请求会写入两个集群中:主和备。只有当两个都成功的请求下,才会告知 client 这次写是成功的。如下图所示:
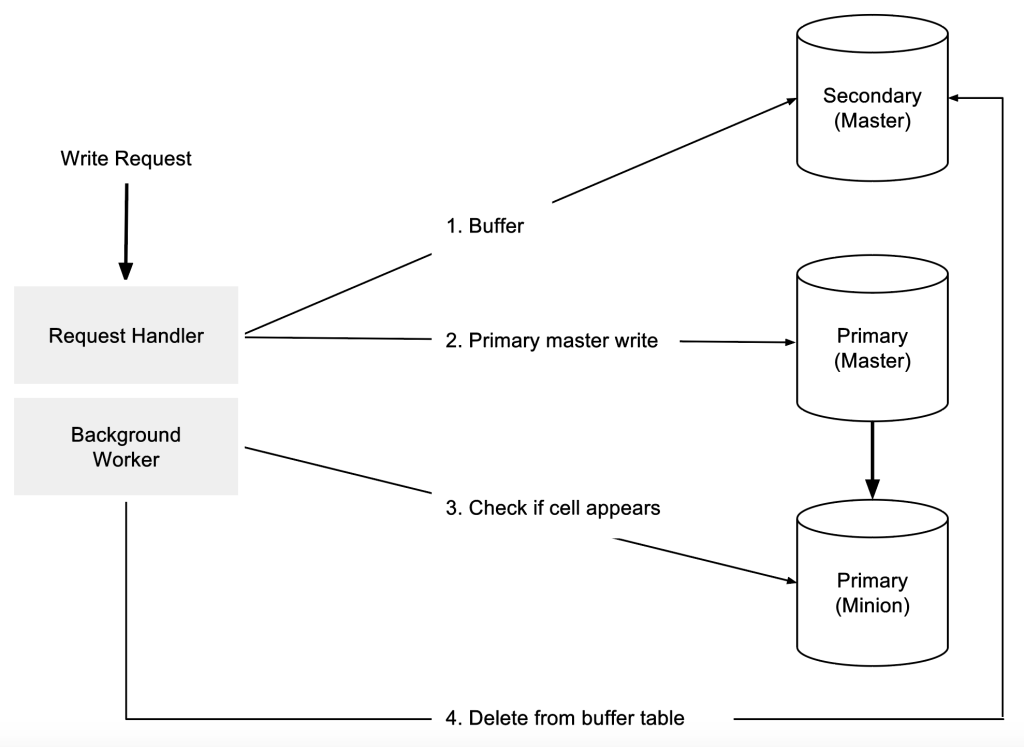
The primary master is where the data is expected to be found on subsequent reads. In case the primary cluster’s master goes down before the asynchronous MySQL replication has replicated the cell to the primary minions, the secondary master serves as a temporary backup of the data.
主 master 在随后的读取中是希望能够读取到数据的。当主 master 宕机时,在 Mysql 的异步复制这个 cell 到主的 minions 节点之前,备 master 充当临时的备份。
The secondary master is chosen at random, and the write goes into a special buffer table. A background job monitors the primary minions for when the cell appears; only then does it delete the cell from the buffer table. Having the secondary cluster means all data is written on at least two hosts. Additionally, the number of secondary masters is configurable.
备 master 是随机选取的写入到一个特别的 buffer table 中。worker 节点会有个后台任务监控是否主 master 的 minions 节点是否存在 cell 数据, 只有当数据已经复制到了 minions 中,才会删除 buffer table 中的数据。有了备 master 意味着所有的数据至少会写入到两个主机中。此外备 master 是可以配置的。
Buffered writes utilize idempotency; if a cell with a given row key, column name, and ref key already exists, the write is rejected. The idempotency aspect means that as long as the buffered cells have a different row key, column name, and ref key, they will all be written to the primary cluster when its master is back up. On the other hand, if multiple writes with the same row key, column name, and ref key are buffered, then only one of them will succeed; when the primary cluster comes back up, the rest are rejected.
buffered writes 是写幂等的,如果给定的 row key,columns name,和 ref key 已经存在,这个写入会被拒绝。 幂等性以为缓冲的 cell 有这不同的 row key,columns name 和 ref key, 当 master 恢复时,这些数据都会写入 master 中。 同样的,当多个同一个 row key,columns name 和 ref key 写入 buffer 中,只有一个会成功。当 master 恢复时,其余的都会被拒绝。
Using MySQL as a Storage Backend
A lot of the power (and simplicity) of Schemaless comes from our use of MySQL in the storage nodes. Schemaless itself is a relatively thin layer on top of MySQL for routing requests to the right database. By using MySQL indexes and the caching built into InnoDB, we get fast query performance for cells and secondary indexes.
schemaless 的大量优点就是我们在 storage 节点中使得的是 Mysql。schemaless 自身是一个相对简单在 mysql 之上提供路由功能。 通过 Mysql 的 indexes 和 InnoDB 内置的 cache,我们获取到很快的查询功能和二级索引。
Each Schemaless shard is a separate MySQL database, and each MySQL database server contains a set of MySQL databases. Each database contains a MySQL table for the cells (called the entity table) and a MySQL table for each secondary index, along with a set of auxiliary tables. Each Schemaless cell is a row in the entity table and has the following MySQL table definition:
每一个 schemaless 分片就是一个单独的 Mysql 数据库实例,每一个 Mysql 数据库实例可以包含一系列的数据库。每一个数据库为 cell 设计一个 Mysql 的表, Mysql 的表会一个二级索引,这个是有一系列的辅助表组成的。每一个 cell 是 table 中的一条记录,这个定义如下:
| Name | Type |
|---|---|
| added_id | int,auto-increment |
| row_key | uuid |
| column_name | string |
| ref_key | int |
| body | blob |
| created_at | datetime |
The added_id column is an auto-increment integer column, and it is the MySQL primary key for the entity table. Having added_id as the primary key makes MySQL write the cells linearly on disk. Furthermore, added_id serves as a unique pointer for each cell that Schemaless triggers use to efficiently extract cells in order of insertion time.
added_id 列是一个自增的整形数据,这个也是 Mysql 的主键在这个表中。added_id 作为主键使得 Mysql 写入 cell 是在磁盘上是线性的。 此外,added_id 唯一性的指向一个 cell,schemaless 触发器能够高效的按照插入时间来处理 cell。
The row_key, column_name, and ref_key columns contain, unsurprisingly, the row key, column name and ref key for each Schemaless cell. To efficiently look up a cell via these three, we define a compound MySQL index on these three columns. Thus, we can efficiently find all the cells for a given row key and column name.
row_key, column_name, 和 ref_key 也可以唯一性在 schemaless 系统标示一个 cell。为了高效的查询这个 cell,我们在 Mysql 中在这三列上定义一个 index。 因此,我们可以高效的根据 row key 和 column name 来查询。
The body column contains the JSON object of the cell as a compressed MySQL blob. We experimented with various encodings and compression algorithms and ended up using MessagePack and ZLib due to the compression speed and size. (More on this in a future article.) Lastly, the created_at column is used to timestamp the cell when we insert it and is useable by Schemaless triggers to find cells after a given date.
body column 是一个 JSON 对象,使用的 Mysql 的 blob 数据存储。我们尝试了各种编码和压缩算法, 从压缩速度和大小上最后选择了 MessagePack 和 ZLib 算法(这个将来会有单独的文章)。 最后,created_at cell 写入时的时间戳,被 schemaless 触发器用来根据时间来查找这个 cell。
With this setup, we let the client control the schema without making changes to the layout in MySQL; we are able to look up cells efficiently. Furthermore, the added_id column makes inserts write out linearly on disk so we can efficiently access the data as a partitioned log.
有了这些设置,我们可以让 client 端来控制 schema,而无需改变 Mysql 中的布局;我们可以看到 cell 是高效的。此外, added_id column 使得我们写入磁盘是线性的, 所有我们可以像分区日志一样高效的获取数据 。
Summary
Schemaless today is the production datastore of a large number of services in Uber’s infrastructure. Many of our services rely heavily on the high availability and scalability of Schemaless.
现在 schemaless 系统大量存在 uber 的基础设施中。大量的服务已经使用了这个高可用,高可扩展的 schemaless 系统。