Raft
2016-01-22
最近研究了 docker,kubernetes,等好玩的开源系统,学习了 Golang 语言,并且研究了 Golang 的源代码, 最后得出一个结论,分布式系统开发已经迎来了春天,前面的 docker,kubernetes 等明星项目都是用 Golang 编写, 研究了 Golang 的源码后,发现确实 Golang 适合编写开发大规模的分布式系统, 不愧为 21 世纪的 C 语言,现在我们的底层工具正在经历使用 Golang 重新构建的过程。既然是分布式系统, 必然是通过多个应用协同工作的,这其中必然要解决一个棘手的问题:Distributed Consensus, 在 java 工具栈中已经存在这么一个模板是的项目了 Zookeeper,zk 使用的算法是 paxos, 这个算法已经通过 Hadoop 系统的大规模引用检验了其的可靠性。但是 paxos 算法也存在一个缺点,就是理解非常困难, 所以 Stanford 提出了这个逻辑上更加容易理解的 Raft 算法。Raft 算法在 Golang 中已经存在一些模板的实现了如:etcd,InfluxDB 等。 下面我对 Raft 协议的解释,大量的参考了Raft 协议动画版。
Why
我们为什么需要这样一个算法呢?这个问题的伴随着 distributed system 的出现,我们开发分布式系统的主要是为了解决单点故障和 scale 的问题, 这两个问题的一般的做法都是使用多台机器多个应用协调工作来解决的,这个是有个数据模型的,举例来说,假设我们的物理机器一年的宕机概率是 10%, 这个概率的宕机就会造成全年 36.5 天的时间不可用,但是我们如果是使用 3 台机器来工作,只有当 3 台机器全部宕机时,服务才不可用,那么我们的宕机概率是 10%10%10% = 0.001%,那么我们就可以将全年的不可用时间降到 5.25 分钟。具体的对比数据如下:

What
上面我们已经知道了为什么需求这么一个分布式一致性的算法,那我们现在就能看看 Raft 的一些细节,看看不是比较容易理解。这其中涉及到俩个过程, Leader Election,和 Log Replication。
Leader Election
为什么需要 leader election 呢?这是因为分布式系统中,都是多台机器系统工作,但是我们知道, 当只有一台机器时,我们要保持这台机器的数据一致性是比较容易做到的,所以分布式系统一般多有一个 leader 几点的概念,所有的操作都需要经过 leader, 然后 leader 节点将这个结果告诉所有的其他几点,当系统中有大多数节点收到这个数据时,leader 才会提交这个数据,并且告诉其他几点这个更新已经接受了。 既然需要一个 leader 这样的几点,我们系统的所有几点应该是对等的,那么怎么产生这个节点的过程,就是 Leader Election。我们看看 Raft 是如何做的:
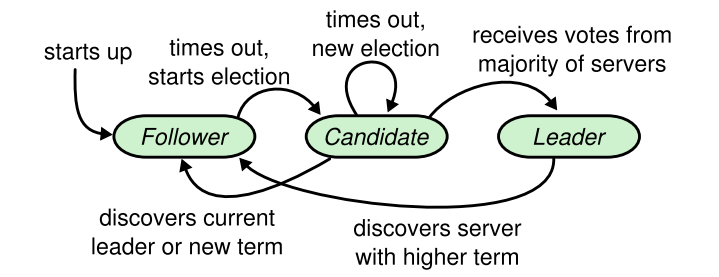
根据上面的状态图来解释下这个过程:
- 刚开始系统中的所有机器多是 Follower 状态。
- Follower 状态的节点经过 100-300ms 中的一个随机值,将成为 Candidate 状态。
- Candidate 状态投自己一票,然后向其他节点邀票,其他节点收到邀票后,发现没有投过这个票,会应答同意这个邀票
- Candidate 收到系统中大多数的投票后会成为 Leader 节点,Leader 节点向系统中的其他节点发送自己已经是 Leader 节点了。
- Leader 节点会周期性的发送 heartbreat 消息重置 Follower 节点的 election timeout。
- 若是 Follower 超过一定的时间没有收到 heartbreat 消息,将系统回退到刚开始说的情况。
这就是 Leader Election 过程中涉及到的状态迁移,这其中有两个重要的超时器,是 election timeout 和 heartbeat timeout。 这样选举过程的解释也就完了,但是我们得考虑比较极端的情况,当系统中有两个 Follower 节点同时成为 Candidate,Candidate节点又同时 获取到了大多数的票,这种情况 Raft 是如何处理的呢?系统这样的情况回退到重新选举来解决中问题,知道可以选举到一个 Leader 为止。
Log Replication
上面已经解释过了 Leader 的选举过程了,那么数据在系统中是如何变更的,我们刚刚说过了一台机器的数据一致性是比较容易实现的, 分布式系统中我们也借鉴这种做法,首先所有的数据都必须经过 Leader,Leader 将这个变更告诉给系统中的所有节点, 当 Leader 收到系统中大多数的节点应答时,才会将这个变更记录提交,并且告诉 client 这个操作成功了。在这个过程中同样存在一个问题, 当系统的多台节点发生 network partitions,也就是我们系统发生了网络故障,将我们的系统分隔成了两个或者多个网络, 这样只要我们的系统中设置的初始系统节点数是一个奇数,分隔成两个系统后,仍然是有个系统中的 leader 能获取到整个系统的大多数票数, 这时系统仍然对外可以工作,当我们手工修复网络问题或,分隔的另外一个系统,由于 client 端提交的变更不能获取到大多数的票数, 所以系统的数据变更都处于未提交状态,这时网络问题已经修复,这个未提交的变更都会回撤,然后应用正常数据的 Log,系统又回到了正常状态。
How
从上面的 Raft 协议的细节可以看到,无论是 election 过程中的 split vote 问题, 还是 replication 过程中的 network partitions,只要我们保证系统的设置时奇数台节点,就可以比较好的避免和解决问题。