Uber's Schemaless Datastore part three
2016-02-29
这篇文章将讲述 schemaless 系统中触发的使用和细节。
Schemaless triggers is a scalable, fault-tolerant, and lossless technique for listening to changes to a Schemaless instance. It is the engine behind our trip processing workflow, from the driver partner pressing “End Trip” and billing the rider to data entering our warehouse for analytics. In this last installment of our Schemaless series, we will dive into the features of Schemaless triggers and how we made the system scalable and fault-tolerant.
schemaless 的触发器是一个可扩展,容错,技术无损的监听 schemaless 数据变化监控器。它是我们 trip 数据处理引擎,从司机按下 “End Trip” 到乘客的账单生成, 和数据分析都是这个来驱动的。这个是我们 schemaless 系统系列的最后一部分,我们将深入探讨 schemaless 系统的触发器特性和系统的可扩展性和容错性的特性。
To recap, the basic entity of data in Schemaless is called a cell. It is immutable, and once written, it cannot be overwritten. (In special cases, we can delete old records.) A cell is referenced by a row key, column name, and ref key. A cell’s content is updated by writing a new version with a higher ref key but same row key and column name. Schemaless does not enforce any schema on the data stored within it; hence the name. From Schemaless’s point of view, it just stores JSON objects.
回顾一下,schemaless 系统的最基本的数据单元叫做 cell。它是不可变的,只能写入一次,不能写覆盖(特殊情况下能够删除老的记录)。一个 cell 通过 row key, column name 和 ref key 来标示。一个 cell 中的内容是通过写入一个更高版本的 ref key 来更新的。schemaless 对数据不强制要求 schema。 从 schemaless 系统的角度来看,cell 就是一个 JSON 对象。
Schemaless Triggers Example
Let’s see how Schemaless triggers works in practice. The code below shows a simplified version of how we do billing asynchronously (UPPERCASE denotes Schemaless column names). The example is in Python:
我们来看看实际中 schemaless 的触发器。下面的代码简单的展示了我们如何异步处理账单(大写代表 schemaless 中的 column name)。 这个例子使用的 python 代码:
# We instantiate a client for talking with the Schemaless instance.
schemaless_client = SchemalessClient(datastore='mezzanine')
# We register the bill_rider function for the BASE column.
@trigger(column='BASE')
def bill_rider(row_key):
# row_key is the UUID of the trip
status = schemaless_client.get_cell_latest(row_key, 'STATUS')
if status.is_completed:
# This means we have already billed the rider.
return
# Otherwise we try to bill.
# We fetch the base trip information from the BASE column
trip_info = schemaless_client.get_cell_latest(row_key, 'BASE')
# We bill the the rider
result = call_to_credit_card_processor_for_billing_trip(trip_info)
if result != 'SUCCESS':
# By raising an exception we let Schemaless triggers retry later
raise CouldNotBillRider()
# We billed the rider successfully and write it back to Mezzanine
schemaless_client.put(row_key, status, body={'is_completed': True, 'result': result})
We define the trigger by adding a decorator, @trigger, on a function and specifying a column in the Schemaless Instance. This tells the Schemaless triggers framework to call the function—in this case, bill_rider—whenever a cell is written to the given column. Here, the column is BASE, and a new cell written in BASE indicates that a trip has finished. This fires the trigger, and the row key—here, it’s the trip UUID—is passed into the function. If more data is needed, the programmer has to fetch the actual data from the Schemaless instance—in this case, from Mezzanine, the trip store.
我们定义一个触发器是通过 @trigger 来注解的,在一个函数中指定一个 column 名称。这个高速 schemaless 触发器将在这种情况下调用。无论如何乘客的账单都将写入给定的 column 中。在这里是 BASE column,当 BASE 列写入数据一个新数据时,表明这个 trip 就完成了。触发器将触发处理 row key,这里是 trip 的 UUID 将传递给这个函数。如果需要更过的数据, 程序会通过 Mezzanine 来获取实际的数据。
The flow of information for the bill_rider trigger function is shown in the diagram below for the case where the rider is billed. The directions of the arrows indicate the caller and callee, and the numbers next to them indicate the order of the flow:
下面的乘客账单触发器函数展示了乘客账单的生成。箭头是从调用者指向被调用者,数字表明的是这个流程的顺序:
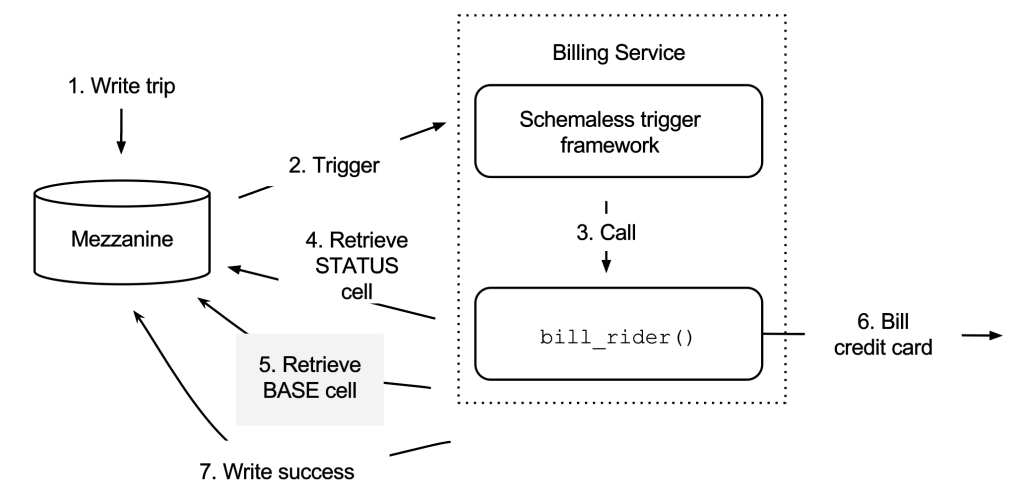
First the trip enters Mezzanine, which makes the Schemaless Trigger framework call bill_rider. When called, the function asks the trip store for the latest version of the STATUS column. In this case the is_completed field does not exist, which means the rider has not been billed. The trip information in the BASE column is then fetched and the function calls the credit card provider that will bill the rider. In this example we succeed in charging the credit card, so we write back success to Mezzanine and set is_completed to True in the STATUS column.
首先 trip 进入 Mezzanine,这个使得 schemaless 系统触发乘客账单。这时,这个函数会查找最新的 STATUS column 数据。如果 is_completed 属性不存在, 这就意味这账单还未支付成功。BASE column 上的 trip 信息,可以提供乘客的信息这样就可以找到乘客的信用卡用来支付。在这个例子中,我们成功的从信用卡中支付成功了, 所以我们可以回写成功到 Mezzanine 的 STATUS column 中的 is_completed 属性中。
The trigger framework guarantees that the bill_rider function is called at least once for every cell in the Schemaless instance. A trigger function is fired typically once, but in case of errors either in the trigger function or transient errors outside of the trigger function, it may be called multiple times. This means that the trigger function needs to be idempotent, which in this example is handled by checking whether the cell has already been processed. If so, the function returns.
触发器系统保证客户账单函数至少调用一次,当 cell 在 schemaless 系统中初始化时。一个触发器函数一般只触发一次,但是当触发器发生故障,或者外部瞬间错误,这是可能会触发多次。 这意味触发器需要是幂等的,这里我们的做法师判断这个 cell 是否已经处理过了,如果处理过了,就直接返回。
As you read about how Schemaless supports this flow, keep the example in mind. We’ll explain how Schemaless can be viewed as a log of changes, discuss the API as it relates to Schemaless, and share the techniques we use to make the flow scalable and fault-tolerant.
我们知道了 schemaless 系统的流程,下面我们将讨论 schemaless 作为日志处理系统的相关 API,可宽展和容错性的技术。
Schemaless as a Log
Schemaless contains all cells, which means it contains all versions for a given row key, column key pair. Because it holds this history of cell versions, Schemaless acts as a log of change in addition to a random-access key-value store. In fact, it is a partitioned log, where each shard is its own log, as shown in the diagram below:
schemaless 包含所有的 cells,这就意味它包含着所有给定的的 row key,column 对版本的 cell。因为它包好所有的 cell 的历史版本, schemaless 实际上是一个日志一样的可随机进入的 key-value 系统。事实上,对于每一个分区就是一个分区日志,如下图所示:
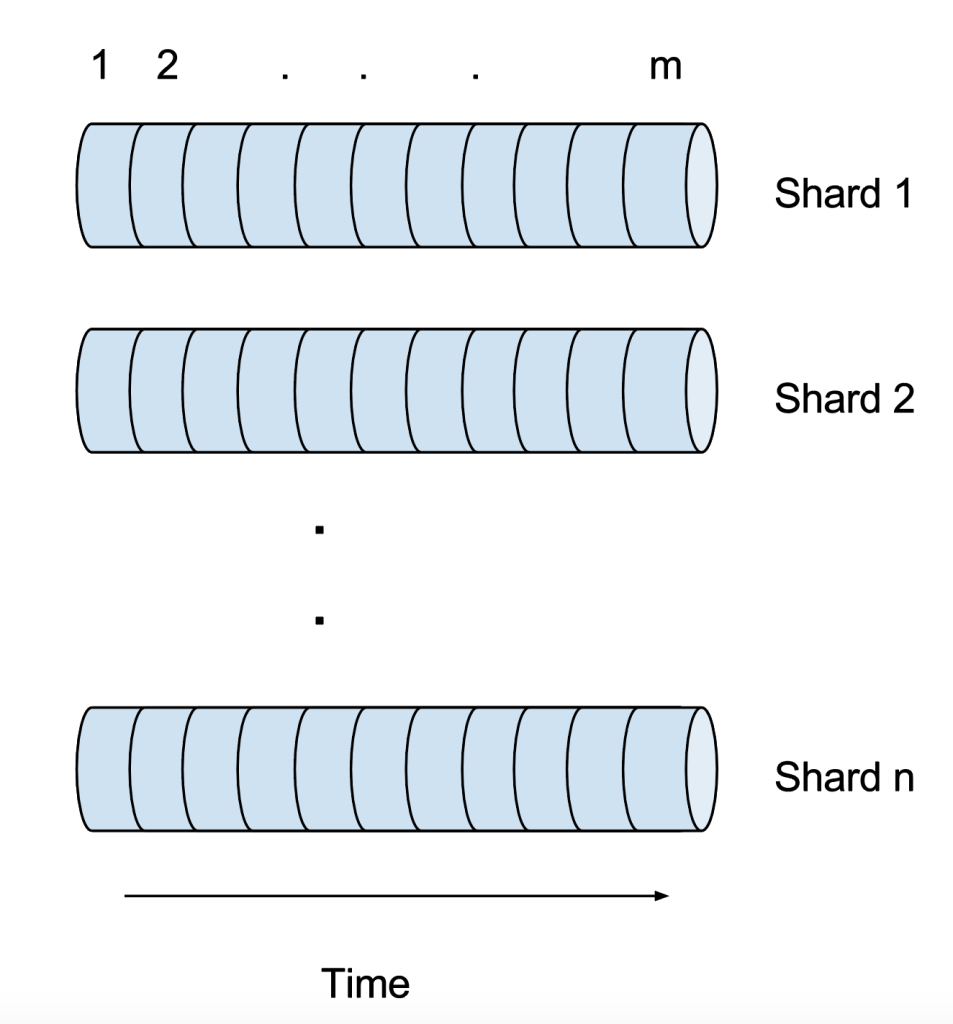
Every cell is written to a specific shard based on the row key, which is a UUID. Within a shard, all cells are assigned a unique identifier, called the added ID. The added ID is an auto-incrementing field that denotes the insertion order of the cells (newer cells will get higher added IDs). In addition to the added ID, every cell has a datetime for when the cell was written. The added ID for a cell is identical on all replicas of the shard, which is important for failover cases.
每一个 cell 被写入到了一个特定的分片中,这个是更具 row key 来分布的。在一个分片中,所有的 cell 被分配了一个唯一性的标示,这里是 added ID。 added ID 是一个自增的字段,这就表明所有的 cell 插入将会是顺序的。除了 added ID,cell 还有一个时间字段。added ID 主要是为了在一个分片中标示一个 cell, 这个对于失败时是非常重要的。
The Schemaless API supports both random access and log-style access. The random-access API addresses individual cells, each identified by the triple row_key, column_key, ref_key:
schemaless API 支持随机读取,每一个 cells 是通过 row_key, column_key, ref_key 对来标示的:
put_cell (row_key, column_key, ref_key, cell):
// Inserts a cell with given row key, column key, and ref key
get_cell(row_key, column_key, ref_key):
// Returns the cell designated (row key, column key, ref key)
get_cell_latest(row_key, column_key):
// Returns the cell designated (row key, column key) with the highest ref key
Schemaless also contains batch versions of these API endpoints, which we omit here. The trigger function bill_rider, shown earlier, uses these functions to retrieve and manipulate individual cells.
schemaless 也可以批量获取,这里我们忽略了。为了简单起见,我们使用账单的触发器函数来获取和维护每一个 cells。
For the log-style access API, we care about the shard number and timestamp and added ID (collectively called location) of the cells:
对于像日志一样的获取 API,我们关心的是分片的标示,时间戳,和 added ID:
get_cells_for_shard(shard_no, location, limit):
// Returns ‘limit’ cells after ‘location’ from shard ‘shard_no’
Similarly to the random-access API, this log-access API has some more knobs to use to batch fetch cells from multiple shards at once, but the above endpoint is the important one. The location can either be timestamp or added_id. Calling get_cells_for_shard returns the next added ID in addition to the cells. For example, if you call get_cells_for_shards with location 1000 and ask for 10 cells, the next location offset returned would be 1010.
和随机读取 API 相似,log-access API 也是通过这些槽位来批量获取 cells 从多个分片中,但是上面的 API 是从一个特定一个中。 通过时间错,或者 added_id 来定位一个分片。调用 get_cells_for_shard 返回下一个 added ID。例如:如果我们调用 get_cells_for_shards 在 1000 这个分片中的 10 个 cell,这个将返回 1010 这个偏移值。
Tailing the Log
With the log-style access API you can tail a Schemaless instance, much like you would tail a file on your system (e.g., tail -f) or an event queue (e.g., Kafka) where the latest changes are polled. The client then keeps track of the offsets seen and uses them in the polling. To bootstrap the tailing, you start from the first entry (i.e., location 0) or from any time or offset after.
在 log-style API 中,我们一个跟踪一个 schemaless 实例,和我们使用一个 tail 命令跟踪一个文件(例如:tail -f)和一个事件队列(例如:Kafka)非常相像。 client 就可以跟踪这个偏移量,使用它们来轮训。为了启动 tailing,我们可以从第一个位置开始,也可以从任何事件任何位置开始。
Schemaless triggers accomplishes the same tailing by using the log-style access API, and it keeps track of the offsets. The benefit over polling the API directly is that Schemaless triggers makes the process fault-tolerant and scalable. Client programs link into the Schemaless triggers framework by configuring which Schemaless instance and which columns to poll data from. Functions or callbacks are attached to this data stream in the framework and are called, or triggered, by Schemaless triggers when new cells are inserted into the instance. In return, the framework spins up the desired number of worker processes on the hosts where the program is running. The framework divides the work over the available processes and handles failing processes gracefully, by spreading the work from the failing process over the remaining healthy processes. This division of work means that the programmer only has to write the handler (i.e., trigger function) and make sure it’s idempotent. The rest is handled by Schemaless triggers.
Schemaless trigger 通过使用日志类访问API完成相同的追踪,并保持追踪偏移。轮询API的好处直接表现在,通过Schemaless trigger让这个过程具有可扩展性与容错性。 通过配置从哪个Schemaless实例、哪一列开始轮询数据,将客户端程序与Schemaless trigger框架链接。 使用的函数或回调与框架中的数据流相关,在新单元格插入实例时通过Schemaless trigger或调用或触发。 反过来,通过框架在程序所运行的主集群中找到要找的工作进程。框架将工作分到可用进程中,然后通过将分到故障进程的工作分配给其他可用进程,巧妙地解决出现故障的进程。 work分配代表着程序员只用编写处理程序(比如trigger函数),并确保它是幂等的。剩下的交给Schemaless trigger来处理。
Architecture
In this section, we will discuss how Schemaless triggers scales and minimizes the impact of errors. The diagram below shows the architecture from a high-level perspective, taking the billing service example from earlier:
在这一节中,我们将讨论如何扩容 schemaless 触发系统,和最小化错误的影响。下图展示了更高级别的架构,我们以上面的订单为例子:
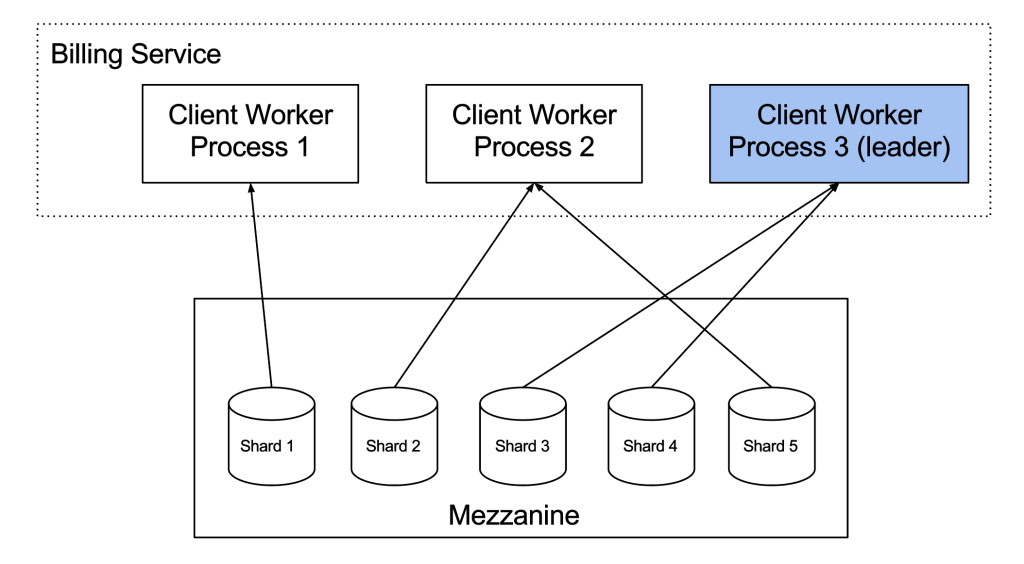
he billing service that uses Schemaless triggers runs on three different hosts, where we (for brevity) assume one worker process per host. The Schemaless triggers framework divides the shards between the worker processes so that only one worker process handles a specific shard. Notice that Worker Process 1 pulls data from shard 1, while Worker Process 2 handles shards 2 and 5, and Worker Process 3 handles shards 3 and 4. A worker process only deals with cells for the assigned shards by fetching new cells and calling the registered callbacks for these shards. One worker process is designated leader and is responsible for assigning shards to worker processes. If a process goes down, the leader reassigns the shards for the failing process to other processes.
这里订单服务在 3 台不同的机器上使用 schemaless 系统的触发器,这里我们简单起见假定每一个 worker 进程在不同的主机上。schemaless 触发器驱动着 worker 和分片, 所以只有只有个 worker 处理一个特定的分片。主要到,分片 1 推送数据到了 worker 1 处理节点,而 worker 2 节点处理分片 2 和 5 的数据,worker 3 处理分片 3 和 4 的数据。 一个 worker 节点仅仅处理分配的分片,他们只会调用这些分片的回调函数。一个 worker 节点会作为这里节点的 leader 节点,它来分配这些关系。如果其中有节点宕机,leader 节点会失败节点上的分片路由到其他的 worker 节点上。
Within a shard, cells are triggered in the order in which they were written¹. This also means that if the triggering of a particular cell always fails due to a programmatic error, it will stall cell processing from that shard. To prevent delays, you can configure Schemaless triggers to mark cells that fail repeatedly and put them on a separate queue. Schemaless triggers will then continue with the next cell. If the number of marked cells exceeds a certain threshold, the triggering stops. This often indicates a systematic error, which needs to be fixed by a human.
在一个分片中,cells 会的触发是顺序的,这个顺序是有它们写入的顺序决定的。这就意味如果一个 cell 由于程序失败导致了触发器的失败,这将导致这个 cell 和面的数据也会失败。 为了解决延迟问题,我们可以配置 schemaless 触发器的行为,如配置触发器失败重试的次数,获取将他们放入一个单独的队列中。触发器总是继续执行下一个 cell 的事件动作。如果这个失败的动作 超过了阀值,我们将停止触发器的行为。这时一般是出现了系统错误,这个可能需要人为干预修复。
Schemaless triggers keeps track of the triggering process by storing the added ID of the latest successfully triggered cell for each shard. The framework persists these offsets to a shared storage, such as Zookeeper or the Schemaless instance itself, which means that if the program is restarted, the triggering will continue from the offsets stored in the shared storage. The shared storage is also used for meta-info, such as coordinating the leader election and discovering added or removed worker processes.
schemaless 触发器系统持续跟踪这个系统最近处理成功的 cell added ID。这个框架会持久化这个偏移量到存储系统中,例如 Zookeeper 或者 schemaless 系统自身中, 这就意味这,当应用程序重启,这个触发器可以从这个偏移量重新开始。这个存储系统也会存储原始信息,例如 leader 选举信息,worker 节点的增加和移除信息。
Scalable and Fault-Tolerant
Schemaless triggers is designed for scalability. For any client program, we can add worker processes up to the number of shards (typically 4096) in the tailed Schemaless instance. Moreover, we can add or remove workers online to handle varying load independently of other trigger clients for a Schemaless instance. By keeping track of the progress purely in the framework, we can add as many clients as possible for the Schemaless instance to send data to. There is no logic on the server side to keep track of the clients or push state to them.
schemaless 触发器被设计为可扩展的。对于任何 client 程序来说,我们添加 worker 节点的数量来处理分片。更多的是,为了处理 client 的变化负载时, 我们可以在线添加或者移除 worker 节点。纯从技术角度上,我们添加任意多的 client 处理程序。因为这个在服务端是无逻辑处理,无状态的。
Schemaless triggers is also fault-tolerant. Any process involved can go down without hurting the system:
schemaless 触发器也是可容错的。任务进程宕机对于系统来说是无害的:
- If a client worker process goes down, the leader will distribute the work from the failing process, ensuring that all shards get processed.
- If the leader among the Schemaless triggers nodes goes down, a new node will be elected as leader. During leader election, cells are still processed, but work can’t be redistributed and processes can’t be added or removed.
- If the shared storage (e.g., ZooKeeper) goes down, cells are still processed. However, like during leader election, work can’t be redistributed and processes can’t be changed while shared storage is down.
- Lastly, the Schemaless triggers framework is insulated from failures inside the Schemaless instance. Any database node can go down without problem, since Schemaless triggers can read from any replica.
- 如果 worker 进程宕机,这个 leader 节点会将这个失败的 worker 节点摘除,并且将任务发送给其他的 worker 节点处理,确保这个事件都能处理到。
- 如果是 leader 节点宕机,会选举一个新的 leader 节点。在选举的过程中,cells 的处理是停止的,但是工作是无法重新分配,流程是不能添加或者删除的。
- 如果是共享存储宕机(如:zookeeper),cell 也会停止处理,工作也不能重新分配,流程不回被共享存储系统记录下来。
- 最后,schemaless 触发器框架对失败时隔离的。任何数据可节点在没有问题的情况可以下线,这是应为 schemaless 触发器可以从复制节点中读出数据。
Summary
From an operational side, Schemaless triggers has been a pleasant companion. Schemaless is the ideal storage for source of truth data, as the data can be accessed via the random-access API or via its log-style access API. Using Schemaless triggers on top of the log-style access API decouples the producers and consumers of the data, allowing the programmer to focus on processing and ignore any scaling and fault-tolerance issues. Finally, we can add more storage servers at runtime to increase the data capacity as well as performance as we get more spindles and memory. Today, the Schemaless triggers framework drives the trip processing flow, including ingestion into our analytics warehouse and cross-datacenter replication. We are excited about its prospects for the remainder of 2016 and beyond.
从操作的方向来看,schemaless 触发器是一个很好的实践。schemaless 是一个理想的存储系统,数据可以随机读取,或者 log-style 的获取。 使用 schemaless 触发器系统,可以从顶层解耦生产者和消费者,可以使得处理程序聚焦在处理的逻辑上,而不用担心系统的可扩展性和容错性问题。 最终,我们通过添加更多的机器来增加数据的容量和获取到很好的性能。现在,schemaless 触发器系统已经在 trip 流程引用了,包括数据仓库中的使用和跨数据中心的复制。 我们对于它的前景感到兴奋。