Uber's Schemaless Datastore part one
2016-02-24
最近看了一些关于大数据存储相关的文章,其中 uber 的 Schemaless Datastore 系统放出了比较的多的干货,我尝试翻译一下 Uber’s Schemaless Datastore 的设计和架构相关文章,最后我们再总结下这个系统的可借鉴点。为了方便国内的用户,我顺便把 uber 中的文章 copy 过来,方便不能访问的用户对照原文理解。
我们首先交代下上下文,uber 大家应该都知道是做什么的,主要业务模型大家也比较熟悉,在 2014 以前 uber 的所有打车缴费记录都是存储在一个节点的 Postgres 中,为了适应日益增长的业务需求,uber 的工程师设计了下面的这套存储系统。
In Project Mezzanine we described how we migrated Uber’s core trips data from a single Postgres instance to Schemaless, our fault-tolerant and highly available datastore. This article further describes its architecture and the expanded role Schemaless has had in Uber’s infrastructure, and how it came to be.
在 Mezzanine 项目中我们描述了如何将 uber 的核心 trips 数据从单个 Postgres 实例中迁移到高可用的,fault-tolerant Schemaless 存储系统中。 这篇文章将描述这个 Schemaless datastore 的架构和在 uber 中是如何构建这样一个系统的过程。
Our Race for a New Database
In early 2014, we were running out of database space due to flourishing trip growth. Each new city and trip milestone pushed us to the precipice, to the point where we realized Uber’s infrastructure would fail to function by the end of the year: we simply couldn’t store enough trip data with Postgres. Our mission was to implement the next generation of database technology for Uber, a task that took many months, much of the year, and involved many engineers from our engineering offices around the world.
早在 2014 的时候,我们业务飞速增长,每一次拓展新城市的业务,都使得我们的存储系统饱受压力,我们意识到我们的基础设施无法满足我们的业务发展了: 我们不能简单将 trip 数据存储到 Postgres 实例中。我们的任务是设计下一代的存储系统,这个任务我们经历了非常长的时间跨度,协调了全球多个城市的工程师。
But first, why even build a scalable datastore when a wealth of commercial and open source alternatives already exist? We had five key requirements for our new trip data store:
在构建 scalable datastore 系统之前,我们要自己问一下,是够存在这么一个商业的开源的系统?回到这个问题之前,我们要清楚我们的关键需求:
- Our new solution needed to be able to linearly add capacity by adding more servers, a property our Postgres setup lacked. Adding servers should both increase the available disk storage and decrease the system response times.
- We needed write availability. We had previously implemented a simple buffer mechanism with Redis, so if the write to Postgres failed we could retry later since the trip had been stored in Redis in the interim. But while in Redis, the trip could not be read from Postgres and we lost functionality like billing. Annoying, but at least we did not lose the trip! As time passed, Uber grew, so our Redis-based solution did not scale. Schemaless had to support a similar mechanism as Redis, but favoring write availability over read-your-write semantics.
- We needed a way of notifying downstream dependencies. In the current system, we had processed many trip components simultaneously (e.g., billing, analytics, etc.). This was an error-prone process: if any step failed, we had to retry all over again even if some components were successful. This does not scale, so we wanted to break out these steps into isolated steps, initiated by data changes. We did have an asynchronous trip event system, but it was based on Kafka 0.7. We were not able to run it lossless, so we would welcome a new system that had something similar, but could run lossless.
- We needed secondary indexes. As we were moving away from Postgres, the new storage system had to support Postgres indexes, which meant secondary indexes to search for trips in the same manner.
- We needed operation trust in the system, as it contains mission-critical trip data. If we get paged at 3 am when the datastore is not answering queries and takes down the business, would we have the operational knowledge to quickly fix it?
- 在新的解决方案中我们系统通过添加机器,来线性扩容,这个属性 Postgres 不能满足。添加机器不仅要能增加存储的空间,而且要能够减少系统的响应时间。
- 我们希望是写可用的。之前的系统,我们使用 redis 来充当 buffer,所以如果 Postgres 失效了,我们在随后可以充实将 redis 中的数据刷如 Postgres 中。 但是存在在 redis 中的数据我们是不能从 Postgres 中读取到的,这样随后的业务如订单业务就不能完成。这样虽然是讨厌的,但是我们至少保证了 trip 数据没有丢失, 而且随着 uber 业务的增长,redis 无发线性扩容。所以 schemaless 必须支持像 redis 这样的机制,当失效的时候,能够满足读取写入的数据语义。
- 我们希望存在一种方案能够通知下游依赖的系统。在当前的系统中,我们处理 trip 数据是同时多个组件同步处理(如:订单,分析系统…)。这样就存在一个问题,如果其中一个失败, 我们不得不同时重试所有的组件,即使某些模块的处理是成功的。这样的处理方式,不能够扩展,我们希望将这样的步骤打断隔离起来,通过数据的变化来触发。 我们已经存在一个异步的 trip 事件系统,是基于 Kafka 0.7 版本的。我们无法办证它不丢失数据,所以我们希望新的系统能够提供相似的功能,但是不能丢失数据。
- 我们希望有个二级索引。我们希望新的系统的提供类似 Postgres 的 index 的功能,方便我们按照之前的做法一样搜索一些 trip 数据。
- 我们系统这个系统是可信任的。比如我们在凌晨 3 点的时候获取数据,但是 datastore 不能响应这个查询,遇到这样的问题是,我们能不能够快速修复。
In light of the above, we analyzed the benefits and potential limitations of some alternative commonly-used systems, such as Cassandra, Riak, and MongoDB, etc. For purposes of illustration, a chart is provided below showing different combinations of capabilities of different system options:
根据上面的原则,我们分析下我们常用的系统的长处和短处,例如:Cassandra, Riak, and MongoDB,下图来说明各个系统的特点:
| Linearly scales | Write availability | Notification | Indexes | Ops Trust | |
|---|---|---|---|---|---|
| Option 1 | ✓ | ✓ | ✗ | (✓) | ✗ |
| Option 2 | ✓ | ✓ | ✗ | (✓) | ✓ |
| Option 3 | ✓ | ✗ | ✗ | (✓) | ✗ |
While all three systems are able to scale linearly by adding new nodes online, only a couple systems can also receive writes during failover. None of the solutions have a built-in way of notifying downstream dependencies of changes, so we would need to implement that at the application level. They all have indexes, but if you’re going to index many different values, the queries become slow, as they use scatter-gather to query all nodes. Lastly some systems that we had experience using were single clusters, were not serving user-facing online traffic, and had various operational issues in connection with our services.
上面的三个系统中都满足线性可扩容通过添加机器,只有 Riak 系统能够保证当系统失效时仍可以保证写成功。没有一个方案存在一个内置的消息通知机制, 所有我们得在应用层面来实现这个功能。它们都能有索引,但是如果你的根据不同的值来添加索引,它们使用聚散读写的方式查询将变慢。 我们有一些单独使用这些集群的经验,但是我们没有在线上的环境使用过,而且一些集群中或多或少存在一些问题。
Finally, our decision ultimately came down to operational trust in the system we’d use, as it contains mission-critical trip data. Alternative solutions may be able to run reliably in theory, but whether we would have the operational knowledge to immediately execute their fullest capabilities factored in greatly to our decision to develop our own solution to our Uber use case. This is not only dependent on the technology we use, but also the experience with it that we had on the team.
最后我们决定自己来构建一个满足需求的系统来存储 trip 数据,虽然上面的方案中是构建在可靠的理论上,但是我们还是决定自己开发这么系统。这不仅依赖我们的技术水平, 而且依赖于我们团队的经验。
We should note that since we surveyed the options more than two years ago and found none applicable for the trip storage use case, we have now adopted both Cassandra and Riak with success in other areas of our infrastructure, and we use them in production to serve many millions of users at scale.
我们应该注意到我们调研方案超过了 2 年,发现没有一个适合我们的 trip 数据的存储。我们现在也适配了 Cassandra and Riak 成功的应用到了我们的用户存储中。
In Schemaless We Trust
As none of the above options fulfilled our requirements under the timeframe we were given, we decided to build our own system that is as simple as possible to operate, while applying the scaling lessons learned from others. The design is inspired by Friendfeed, and the focus on the operational side inspired by Pinterest.
上面的可选方案中没有一个全部满足我们需求的,我们觉得自己构建一个这样满足需求的系统,这个系统尽可能的简单对于运维来说, 我们构建这个系统时,设计上我们参考了 Friendfeed,运维上我们参考了 Pinterest 的想法。
We ended up building a key-value store which allows you to save any JSON data without strict schema validation, in a schemaless fashion (hence the name). It has append-only sharded MySQL with buffered writes to support failing MySQL masters and a publish-subscribe feature for data change notification which we call triggers. Lastly, Schemaless supports global indexes over the data. Below, we discuss an overview of the data model and some key features, including the anatomy of a trip at Uber, with more in depth examples reserved for a followup article.
我们构建了一个 key-value 存储系统,它允许我们保存任何 JSON 数据而不需要严格的 schema 检测。这个系统是使用 mysql 构建的,特点是数据以追加形式写入,支持失败 而且当数据发生变化时,能够通知其他系统。最后,schemaless 支持全局的 index,随后我们讨论这个系统的数据模型和一些特性,包括全面的解析 uber 的系统,这些会在随后的文章给出。
The Schemaless Data Model
Schemaless is an append-only sparse three dimensional persistent hash map, very similar to Google’s Bigtable. The smallest data entity in Schemaless is called a cell and is immutable; once written, it cannot be overwritten or deleted. The cell is a JSON blob referenced by a row key, a column name, and a reference key called ref key. The row key is a UUID, while the column name is a string and the reference key is an integer.
schemaless 是一个追加写入,三维稀疏 hash map,这个和 Google 的 Bigtable 系统非常相似。在 schemaless 中最小的数据单元叫做 cell,它是不可变; 一旦写入,就不能覆盖或者删除。cell 是一个 JSON blob,可以通过一个 row key,column name 和 reference key 来引用。row key 是一个 UUID, column name 是个 string,reference key 是个整形数据。
You can think of the row key as a primary key in a relational database, and the column name as a column. However, in Schemaless there is no predefined or enforced schema and rows do not need to share column names; in fact, the column names are completely defined by the application. The ref key is used to version the cells for a given row key and column. So if a cell needs to be updated, you would write a new cell with a higher ref key (the latest cell is the one with the highest ref key). The ref key is also useable as entries in a list, but is typically used for versioning. The application decides which scheme to employ here.
你可以将 row key 看成是关系数据库中的主键,column name 是个一个 column。但是,在 schemaless 中不需要提前预定义 schema,也不需要强制定义 schema。 事实上,column name 的定义完全由应用来决定。ref key 被用于版本管理,对于一个确定的 row key 和 column。所有当 cell 需要更新是,我们只需要重新写入一个 cell 但是这个 cell 只需要给定一个更高的 ref key。ref key 也可以作为一个属性,但是一般只是作为版本号,这个完全也由应用程序决定。
Applications typically group related data into the same column, and then all cells in each column have roughly the same application-side schema. This grouping is a great way to bundle data that changes together, and it allows the application to rapidly change the schema without downtime on the database side. The example below elaborates more on this.
应用程序一般使用同一个 column 来分组数据,这时这些 cell 应该有一个大概一致的 schema 对应用程序来说。这样组织数据的方式是非常好的,这样我们可以敏捷的修改应用程序 而不需要在 database 层停机,下面使用一个列子来说明。
Example: Trip Storage in Schemaless
Before we dive into how we model a trip in Schemaless, let’s look at the anatomy of a trip at Uber. Trip data is generated at different points in time, from pickup drop-off to billing, and these various pieces of info arrive asynchronously as the people involved in the trip give their feedback, or background processes execute. The diagram below is a simplified flow of when the different parts of an Uber trip occur:
在我们讲解 schemaless 数据模型之前,我们来大概看看在 uber 中一个 trip 的过程,trip 数据的产生是随时的,账单的产生是线下的,还有各种优惠。我们通过下面一张图来看看:
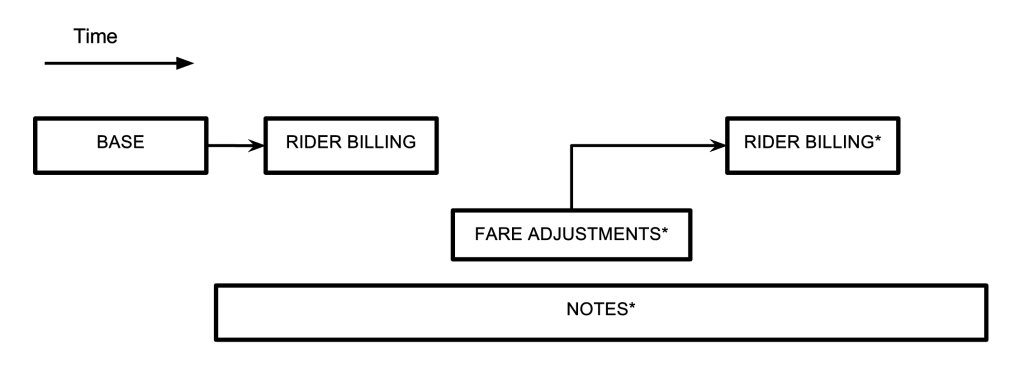
A trip is driven by a partner, taken by a rider, and has a timestamp for its beginning and end. This info constitutes the base trip, and from this we calculate the cost of the trip (the fare), which is what the rider is billed. After the trip ends, we might have to adjust the fare, where we either credit or debit the rider. We might also add notes to it, given feedback from the rider or driver (shown with asterisks in the diagram above). Or, we might have to attempt to bill multiple credit cards, in case the first is expired or denied. Trip flow at Uber is a data driven process. As data becomes available or is added, then certain set of processes will execute on the trip. Some of this info, such as a rider or driver rating (considered part of the notes in the above diagram), could arrive days after the trip finished.
一个 trip 包含 司机,乘客,和一个开始结束时间对。这些信息构成了 base trip,随后的票价的计算就是乘客的账单。在 trip 结束后,我们就需要计算票价,我们记账到乘客和司机两端。 我们可能会添加一些评价,乘客和司机可以相互评价。我们将试图在过个信用卡中扣费,以一种情况是信用卡过期或者拒绝扣款。trip 的流程在 uber 中是数据驱动的。当数据添加时, 一些随后的动作就会发生在这个 trip 上。列如:乘客和司机的相互评价,这个动作可以发生在这个 trip 结束后的很多天。
So, how do we map the above trip model into Schemaless?
如上所述,我们应该怎么设计我们的 trip 数据模型呢?
The Trip Data Model
Using italics to denote UUIDs and UPPERCASE to denote column names, the table below shows the data model for a simplified version of our trip store. We have two trips (UUIDs trip_uuid1 and trip_uuid2) and four columns (BASE, STATUS, NOTES, and FARE ADJUSTMENT). A cell is represented by a box, with a number and a JSON blob (abbreviated with {…}). The boxes are overlaid to represent the versioning (i.e., the differing ref keys).
我们使用斜体来表明 UUIDs,使用大写来表明是 column names,下面这个表格展示了一个最简单的数据模型版本。 我们有两个 trip (UUIDs trip_uuid1 and trip_uuid2) 和四个 columns (BASE, STATUS, NOTES, and FARE ADJUSTMENT). 一个 cell 通过一个 box 来表示,其中包含了一个数字和 JSON blob。这个 box 通过版本的变化来覆盖。
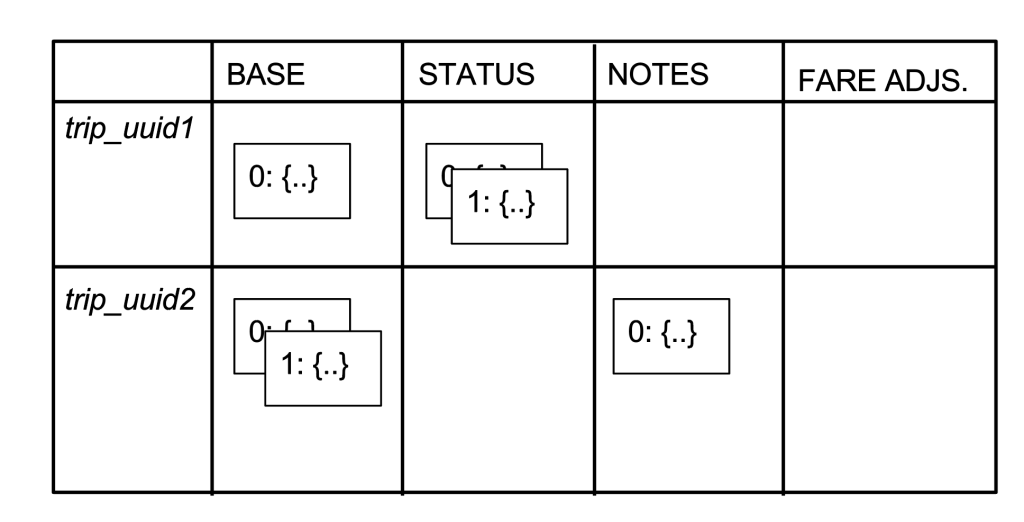
trip_uuid1 has three cells: one in the BASE column, two in the STATUS column and none in the FARE ADJUSTMENTs column. trip_uuid2 has two cells in the BASE column, one in the NOTES column, and likewise none in the FARE ADJUSTMENTS column. For Schemaless, the columns are not different; so the semantics of the columns are defined by the application, which in this case is the service Mezzanine.
trip_uuid1 有 3 个 cell:一个在 BASE column 中,两个在 STATUS column 中,FARE ADJUSTMENTs column 没有数据。 trip_uuid2 的 BASE column 有两个 cells,一个在 NOTES column,通过 FARE ADJUSTMENTS column 列中没有数据。对于 schemaless 中,columns 是不同的, 所以 columns 是由应用程序来定义语义的,这个是在 Mezzanine 完成的。
In Mezzanine, the BASE column cells contain basic trip info, such as the driver’s UUID and the trip’s time of day. The STATUS column contains the trip’s current payment status, where we insert a cell for each attempt to bill the trip. (An attempt could fail if the credit card does not have sufficient funds or has expired.). The NOTES column contains a cell if there are any notes associated with the trip by the driver or left by an Uber DOps (Driver Operations employee). Lastly the FARE ADJUSTMENTs column contains cells if the trip fare has been adjusted.
在 Mezzanine 服务中,BASE columns 包含基本的 trip 信息,例如司机的 UUID,trip 发生的时间。 STATUS column 中包含 trip 的当前支付状态, 每次试图支付时,都会产生一个 cell。NOTES column 包含司机和乘客的评论。最后 FARE ADJUSTMENTs column 包含了这个 trip 的优惠信息。
We use this column split to avoid data races and minimize the amount of data that needs to be written on updates. The BASE column is written when a trip is finished, and thus typically only once. The STATUS column is written when we attempt to bill the trip which happens after the data in the BASE column is written and can happen several times if the billing fails. The NOTES column can similarly be written multiple times at some point after the BASE is written, but it is completely separate from the STATUS column writes. Similarly, the FARE ADJUSTMENTS column is only written if the trip fare is changed, for example due to an inefficient route.
我们使用 column 来分割数据和最小化数据,BASE column 对于一个 trip 一般只会写入一次。 STATUS column 当试图支付这个 trip 是,这个是当 BASE column 写入数据时, 或者当支付失败的时候会写入多次。NOTES column 同样可以写入多次,FARE ADJUSTMENTS 一般情况下也只能写入一次。
Schemaless Triggers
A key feature of Schemaless is triggers, the ability to get notified about changes to a Schemaless instance. Since the cells are immutable and new versions are appended, each cell also represents a change or a version, allowing the values in an instance to be viewed as a log of changes. For a given instance, it is possible to listen on these changes and trigger functions based on them, very much like an event bus system such as Kafka.
schemaless 一个关键的特性是有触发器,schemaless 的数据改变都会获取到通知。因为 cell 是不可变的,新的版本都是追加的,没一个 cell 都代表了一个变化或者一个版本。 这样就允许一个值代表一个变化的日志。对一个给定的实例,它会监听所有的数据变化,这个会基于 Kafka 的事件系统非常相像。
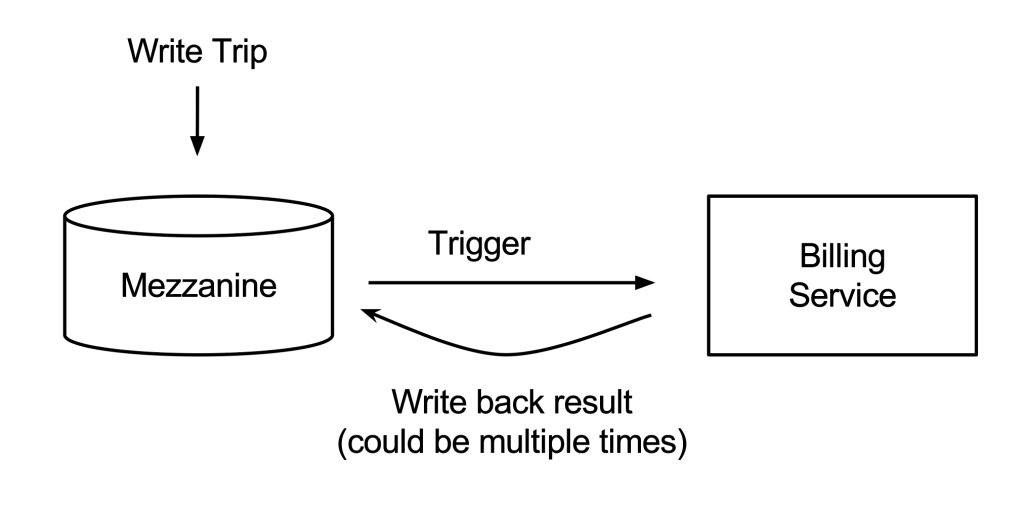
Schemaless triggers make Schemaless a perfect source-of-truth data store because, besides random access to the data, downstream dependencies can use the trigger feature to monitor and trigger any application-specific code (a similar system is LinkedIn’s DataBus), hence decoupling data creation and its processing.
schemaless 的触发器使得这个系统是一个可信任的数据源,数据是可以随机读取的,下游的依赖可以通过触发器来监控数据的变化,应用程序也可以通过这个来解耦数据。
Among other use cases, Uber uses Schemaless triggers to bill a trip when its BASE column is written to the Mezzanine instance. Given the example above, when the BASE column for trip_uuid1 is written, our billing service that triggers on the BASE column picks this cell up and will try to bill the trip by charging the credit card. The result of charging the credit card, whether it is a success or a failure, is written back to Mezzanine in the STATUS column. This way the billing service is decoupled from the creation of the trip, and Schemaless acts as an asynchronous event bus.
举个列子,uber 使用 schemaless 的触发器来触发账单当一个 trip 的 BASE column 被写入时。上面的例子中,当 trip_uuid1 的 BASE column 写入时,我们的账单服务就会 读取 BASE column 的数据来尝试支付。无论是否支付成功,我们将在 STATUS column 中写入数据。账单服务和 trip 的数据解耦了,schemaless 实际上充当了事件总线。
Indexes for Easy Access
Finally, Schemaless supports indexes defined over the fields in the JSON blobs. An index is queried via these predefined fields to find cells that match the query parameters. Querying these indexes is efficient, because the index query only need go to a single shard to find the set of cells to return. In fact, the queries can further be optimized, as Schemaless allows the cell data to be denormalized directly into the index. Having the denormalized data in the index means that an index query only need to consult one shard for both querying and retrieving the information. In fact, we typically recommend Schemaless users to denormalize data that they might think they need into the indexes in case they need to query any information besides retrieving a cell directly via the row key. In a sense, we thereby trade storage for fast query lookup.
最后,schemaless 支持在 JSON blob 属性上定义索引。索引世界上是方面查询预定义的,有索引的查询是高效的,这可以在单个实例中找到所有的 cell。 事实上,这些查询将来还可以优化,schemaless 允许 cell 中的非规范化的数据添加到索引中。建立非规范的数据的索引,意味着一个查询只需要考虑一个实例。 实际上,我们一般只讲非规范数据中有用的数据来建立索引,因为获取一个 cell 是通过 row key,因此我们可以快速的获取到数据。
As an example for Mezzanine, we have a secondary index defined allowing us to find a given driver’s trips.
We have denormalized the trip creation time and the city where the trip was taken.
This makes it possible to find all the trips for a driver in a city within a given time range.
Below we give the definition of the driver_partner_index in YAML format,
that is part of the trips datastore and defined over
the BASE column (the example is annotated with comments using the standard #).
在 Mezzanine 例子中,我们有一个定义在 trip 上的二级索引。我们需要按照创建时间,我城市来获取 trip 数据。二级索引使得获取给定一个时间范围的城市数据成为可能。 下面我们给出了一个 YAML 格式的索引示例,这个是定义在 BASE column 上的。
table: driver_partner_index # Name of the index.
datastore: trips # Name of the associated datastore
column_defs:
– column_key: BASE # From which column to fetch from.
fields: # The fields in the cell to denormalize
– { field: driver_partner_uuid, type: UUID}
– { field: city_uuid, type: UUID}
– { field: trip_created_at, type: datetime}
Using this index, we can find trips for a given driver_partner_uuid filtered by either city_uuid and/or trip_created_at. In this example we only use fields from the BASE column, but Schemaless supports denormalizing data from multiple columns, which would amount to multiple entries in the above column_def list.
使用这个索引我们通过过滤 city_uuid, trip_created_at 来查找 trips。在这个例子中我们仅仅使用了 BASE column 列中的数据,其实 schemaless 支持多个 columns 的 非规范数据建立索引,我只需要在 column_def 中定义多个 columns 就行。
As mentioned Schemaless has efficient indexes, achieved by sharding the indexes based on a sharding field. Therefore the only requirement for an index is that one of the fields in the index is designated as a shard field (in the above example that would be driver_partner_uuid, as it is the first given). The shard field determines which shard the index entry should be written to or retrieved from. The reason is that we need to supply the shard field when querying an index. That means on query time we only need to consult one shard for retrieving the index entries. One thing to note about the sharding field is that it should have a good distribution. UUIDs are best, city ids are suboptimal and status fields (enums) are detrimental to the storage.
通过对切割字段构建 index,使得 schemaless 有一个高效的 index。对于一个 index 来说唯一的要求就是索引的字段是一个切割字段。 切分字段确定哪些碎片索引条目应该写入或检索。原因是我们需要供应切分字段查询索引。这意味着在查询时我们只需要咨询检索索引条目的一个碎片。 有一件事需要注意分片字段是它应该有一个良好的分布。uuid是最好的,城市id和状态不佳字段存储都是不好的。
For other than the shard field, Schemaless supports equality, non-equality and range queries for filtering, and supports selecting only a subset of the fields in the index and retrieving specific or all columns for the row key that the index entries points to. Currently, the shard field must be immutable, so Schemaless always only need to talk with one shard. But, we’re exploring how to make it mutable without too big of a performance overhead.
对于切割字段还说,schemaless 索引支持等于,不等于,和范围过滤查询,支持选择字段的一个子集合和获取指定 columns 的 row key。 当前要求切割的字段是不可变的,所以 schemaless 总是需要和一个 shard 通信。但是我们正在探索使得这个是一个可变,但是不会损失很大的性能。
The indexes are eventually consistent; whenever we write a cell we also update the index entries, but it does not happen in the same transaction. The cells and the index entries typically do not belong to the same shard. So if we were to offer consistent indexes, we would need to introduce 2PC in the writes, which would incur significant overhead. With eventually consistent indexes we avoid the overhead, but Schemaless users may see stale data in the indexes. Most of the time the lag is well below 20ms between cell changes and the corresponding index changes.
索引是最终一致性的;无论我们是写一个 cell 还是更新这个 cell,但是这两个操作是不会发生在一个事务中的。cells 中的数据和 index 中的记录一般情况下是不属于同一个 shard 的。 所以我们如果要提供一致性索引,我们需要引入两阶段提交,这将带了巨大的消耗。使用最终一致性的 index 可以避免这个消耗,这使得 schemaless 中的用户查询到的数据不是最新的。 现在的系统中,我们索引中的数据大概延迟 cell 中的数据 20 ms。
Summary
We’ve given an overview of the data model, triggers and indexes, all of which are key features which define Schemaless, the main components of our trip storage engine. In future posts, we’ll look at a few other features of Schemaless to illustrate how it’s been a welcome companion to the services in Uber’s infrastructure: more on architecture, the use of MySQL as a storage node, and how we make triggering fault-tolerant on the client-side.
上面我们看到了数据模型,触发器,索引,这些关键性的特性在 schemaless 系统是如何定义的。在随后的文章中,我们将看到其他的特性比如:更多架构上信息,如何使用 Mysql 作为一个 存储节点,和如何构建触发器使得是一个可容错的对于 client 端来说。