TCP 状态 TIME_WAIT 分析
2015-08-13
问题描述
线上的服务器出现了问题,表现为一台应用服务器当请求另外一台应用服务器的服务时,出现 read time out 的异常。 当运维尝试了重启应用等操作后,一分钟后症状依旧。我接手问题时首先在出现异常的服务器上使用
[root@docker221 ~]# ss -s
Total: 543 (kernel 1323)
TCP: 197 (estab 165, closed 7, orphaned 0, synrecv 0, timewait 3/0), ports 0
Transport Total IP IPv6
* 1323 - -
RAW 2 1 1
UDP 7 6 1
TCP 190 23 167
INET 199 30 169
FRAG 0 0 0
[root@docker221 ~]#
其中 timewait 状态的统计达到了 5-6W,这个状态这么多,不正常,初步怀疑是这个点产生。通过
[root@docker221 ~]# netstat -naltp | grep TIME_WAIT
命令查看 TIME_WAIT 状态链接详细信息,知道了这些状态信息的产生是 nginx 服务器和应用服务器之间的链接。
问题分析
对于 TIME_WAIT 状态太多的情况,我们来分析下问题。首先我们来看看 tcp 的状态迁移图:
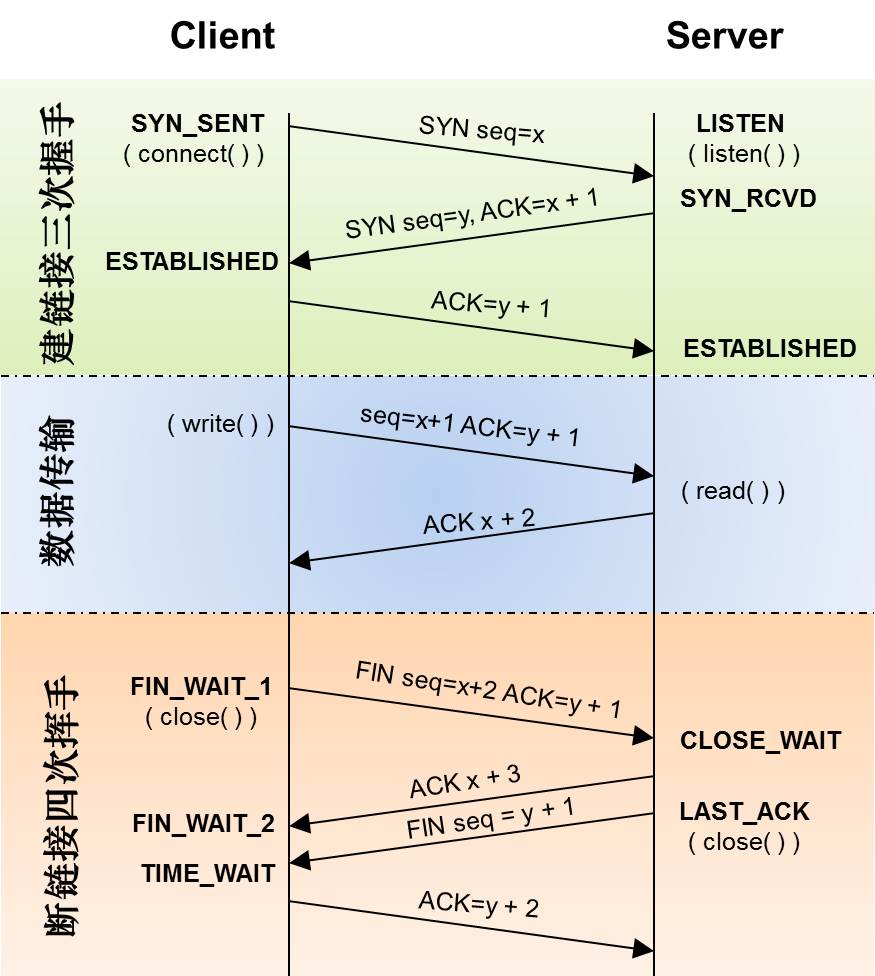
可以看到 TIME_WAIT 状态的产生是tcp 链接的一段主动关闭了链接,才会有 TIME_WAIT。那么解决这个问题的方法就是不主动关闭 tcp 链接。
问题的解决过程
通过上面问题分析,我们知道产生 TIME_WAIT 的产生原因了,和解决办法了,现在就是看看我们该怎么解决。
tcpdump 抓包分析原因
首先我们抓取 nginx 到问题服务器上的包。将包抓好后在 windows 上用 wireshark 打开。因为我们的业务大部分是 http 请求,所以我们关注 http 请求

从上图我们可以发现,http connection 头为 close。 我们可以查看 http 1.1 rfc,
Persistent HTTP connections have a number of advantages:
- By opening and closing fewer TCP connections, CPU time is saved in routers and hosts (clients, servers, proxies, gateways, tunnels, or caches), and memory used for TCP protocol control blocks can be saved in hosts. - HTTP requests and responses can be pipelined on a connection. Pipelining allows a client to make multiple requests without waiting for each response, allowing a single TCP connection to be used much more efficiently, with much lower elapsed time. - Network congestion is reduced by reducing the number of packets caused by TCP opens, and by allowing TCP sufficient time to determine the congestion state of the network. - Latency on subsequent requests is reduced since there is no time spent in TCP's connection opening handshake. - HTTP can evolve more gracefully, since errors can be reported without the penalty of closing the TCP connection. Clients using future versions of HTTP might optimistically try a new feature, but if communicating with an older server, retry with old semantics after an error is reported. HTTP implementations SHOULD implement persistent connections.
这个的意思是说,connection 头是控制是否在一个 tcp 链接中承载多个 http 请求。
知道了这个以后,根据上面抓包的结果我们,知道这个问题应该从 nginx 这一端下手解决,由于现在的请求中 http connection 头是 close,我们应该将其改为 keep-alive,通过查阅 nginx 的文档,我们知道只需要添加下面的配置
server {
...
location /http/ {
proxy_pass http://http_backend;
proxy_http_version 1.1;
proxy_set_header Connection "";
...
}
}
当我们修改 nginx 配置 reload 后,我们再次抓包

通过上图我们发现 http 的 connection 的头确实已经是 keep-alive 了。服务器运行一段时间后应用服务器 上 TIME_WAIT 的链接显著减少,从 6W 下降到 1000 左右。但是这又出现了问题,导致 nginx 服务器上的 TIME_WAIT 状态急剧增加。 在上面的问题分析中,我们 TIME_WAIT 状态的产生是由于关闭了链接产生的,那我们看看下面的截图:

我们可以清晰看到 nginx 服务器关闭了这个 connection 为 keep-alive 的链接。这是导致 TIME_WAIT 状态急剧增加的原因。 那么问题应该还是在 nginx 配置上。通过继续查找 nginx 的配置。
Syntax: keepalive connections; Default: — Context: upstream
This directive appeared in version 1.1.4.
Activates the cache for connections to upstream servers.
The connections parameter sets the maximum number of idle keepalive connections to upstream servers that are preserved in the cache of each worker process. When this number is exceeded, the least recently used connections are closed.
这个指令是开启保持一个 keep-alive 链接的个数。默认是没有值。所有我们应该在配置添加形如以下的配置
upstream memcached_backend {
server 127.0.0.1:11211;
server 10.0.0.2:11211;
keepalive 32;
}
当添加上面的配置后,我们通过 tcpdump 抓包后确认:

我们过滤了端口为 33179 的包,保证是在一个一个链接上,因为抓包的时候就过滤了应用服务器的监听端口。现在我们看到了一个 tcp 链接上有 多个 http 的 request,我们再次确认下,以图中的序列号为 10 的包为例,因为这是一个 http response 包。我们看看是不是下一个 http request 包的 seq 号是接上这个包的 ACK 号,如图:

可以看到序列号为 10 的 ACK 号是 623,序列号 11 的包:
11 2015-08-13 12:29:13.633910 192.168.227.57 192.168.227.72 TCP 54 33179→8002 [ACK] Seq=623 Ack=249 Win=35 Len=0
序列号是 623,但是 Len=0,意味着下一个包的 seq 号应该还是 623:

清楚的看到序列号为 18 的包的 seq 号确实是623,而且是一个 http request,说明这是在一个 tcp 链接上承载了多个 http request。
总结
关于TIME_WAIT数量太多。从上面的描述我们可以知道,TIME_WAIT是个很重要的状态,但是如果在大并发的短链接下,TIME_WAIT 就会太多, 这也会消耗很多系统资源。只要搜一下,你就会发现,十有八九的处理方式都是教你设置两个参数,一个叫tcp_tw_reuse, 另一个叫tcp_tw_recycle的参数,这两个参数默认值都是被关闭的,后者recyle比前者resue更为激进,resue要温柔一些。 另外,如果使用tcp_tw_reuse,必需设置tcp_timestamps=1,否则无效。这里,你一定要注意, 打开这两个参数会有比较大的坑——可能会让TCP连接出一些诡异的问题 (因为如上述一样,如果不等待超时重用连接的话,新的连接可能会建不上。正如官方文档上说的一样 “It should not be changed without advice/request of technical experts”)。
- 关于tcp_tw_reuse。官方文档上说tcp_tw_reuse 加上tcp_timestamps(又叫PAWS, for Protection Against Wrapped Sequence Numbers)可以保证协议的角度上的安全,但是你需要tcp_timestamps在两边都被打开(你可以读一下tcp_twsk_unique的源码 )。我个人估计还是有一些场景会有问题。 - 关于tcp_tw_recycle。如果是tcp_tw_recycle被打开了话,会假设对端开启了tcp_timestamps,然后会去比较时间戳,如果时间戳变大了,就可以重用。但是,如果对端是一个NAT网络的话(如:一个公司只用一个IP出公网)或是对端的IP被另一台重用了,这个事就复杂了。建链接的SYN可能就被直接丢掉了(你可能会看到connection time out的错误)(如果你想观摩一下Linux的内核代码,请参看源码 tcp_timewait_state_process)。 - 关于tcp_max_tw_buckets。这个是控制并发的TIME_WAIT的数量,默认值是180000,如果超限,那么,系统会把多的给destory掉,然后在日志里打一个警告(如:time wait bucket table overflow),官网文档说这个参数是用来对抗DDoS攻击的。也说的默认值180000并不小。这个还是需要根据实际情况考虑。Again,使用tcp_tw_reuse和tcp_tw_recycle来解决TIME_WAIT的问题是非常非常危险的,因为这两个参数违反了TCP协议(RFC 1122)
其实,TIME_WAIT表示的是你主动断连接,所以,这就是所谓的“不作死不会死”。试想,如果让对端断连接,那么这个破问题就是对方的了,呵呵。另外,如果你的服务器是于HTTP服务器,那么设置一个HTTP的KeepAlive有多重要(浏览器会重用一个TCP连接来处理多个HTTP请求),然后让客户端去断链接(你要小心,浏览器可能会非常贪婪,他们不到万不得已不会主动断连接)。
TIME_WAIT 状态存在的理由
- 可靠的实现 TCP 全双工连接的终止
-
允许老的重复的分节在网络中消息
第一个理由是假设最终的 ACK 包丢失,服务端将超市重传最终的 FIN 包,但是 client 端没有维护 TCP 状态,将导致相应一个 RST,server 端将解释为一个错误。
第二个理由是假设我们的 client 网络处于 NAT 的环境中,client 新的链接使用以前的端口。但是以前的重复 ACK 包又重新到达了 server 端,将可能导致新的链接终止。