build uber's geofence service with go
2016-03-02
In early 2015 we built a microservice that does one thing (and does it really well), geofence lookups. One year later, this service is Uber’s highest queries per second (QPS) service out of the hundreds we run in production. Here’s the story of why we built this service, and how the relatively recent Go programming language helped us build and scale it so fast.
早在 2015 的时候,我们构建一个微服务,那就是 geo 查询服务。 一年之前,这个服务是 uber 众多服务中查询负载最高的服务,应为它要服务于 uber 生成环境中上百个服务。 这篇文章将讲述我们为什么要构建这样一个服务,和怎么使用 Go 语言来帮助我们构建这样一个可宽展和高性能的服务。
Background
At Uber, a geofence refers to a human-defined geographic area (or polygon in geometry terms) on the Earth’s surface. We use geofences extensively at Uber for geo-based configurations. This is important for showing users which products are available at a given location, defining areas with specific requirements such as airports, and implementing dynamic pricing in neighborhoods where lots of people are requesting rides at the same time.
在 uber 中,geofence 是一个人为的将地球表面分隔为一个个区域(或者是多边形)。我们使用的 geofences 的大小是可以配置的。 这个是非常重要的对于用户给定的一个位置展示给用户,例如在机场这样的特定区域,我们要实现动态价格,因为这个地方在同一时间可能会有多个乘客的需求。
 An example geofence in Colorado.
An example geofence in Colorado.
The first step to retrieve geolocation-based configurations for something like a lat/lon pair from a user’s mobile phone is to find which geofences the location falls into. This functionality used to be scattered and duplicated in multiple services/modules. But as we move away from a monolithic architecture to a (micro)service-oriented architecture, we chose to centralize this functionality into a single new microservice.
Ready, Set, Go!
Node.js was the real-time marketplace team’s primary programming language at the time we evaluated languages, and thus we had more in-house knowledge and experience with it. However, Go met our needs for the following reasons:
- High-throughput and low-latency requirements. Geofence lookups are required on every request from Uber’s mobile apps and must quickly (99th percentile < 100 milliseconds) answer a high rate (hundreds of thousands per second) of queries.
- CPU intensive workload. Geofence lookups require CPU-intensive point-in-polygon algorithms. While Node.js works great for our other services that are I/O intensive, it’s not optimal in this use case due to Node’s interpreted and dynamic-typed nature.
- Non-disruptive background loading. To ensure we have the freshest geofences data to perform the lookups, this service must keep refreshing the in-memory geofences data from multiple data sources in the background. Because Node.js is single threaded, background refreshing can tie up the CPU for an extended period of time (e.g., for CPU-intensive JSON parsing work), causing a spike in query response times. This isn’t a problem for Go, since goroutines can execute on multiple CPU cores and run background jobs in parallel with foreground queries.
To Geo Index or Not: That is the Question
Given a location specified as a lat/lon pair, how do we find which of our many tens of thousands of geofences this location falls into? The brute-force way is simple: go through all the geofences and do a point-in-poly check using an algorithm, like the ray casting algorithm. But this approach is too slow. So how do we narrow down the search space efficiently?
Instead of indexing the geofences using R-tree or the complicated S2, we chose a simpler route based on the observation that Uber’s business model is city-centric; the business rules and the geofences used to define them are typically associated with a city. This allows us to organize the geofences into a two-level hierarchy where the first level is the city geofences (geofences defining city boundaries), and the second level is the geofences within each city.
For each lookup, we first find the desired city with a linear scan of all the city geofences, and then find the containing geofences within that city with another linear scan. While the runtime complexity of the solution remains O(N), this simple technique reduced N from the order of 10,000s to the order of 100s.
Architecture
We wanted this service to be stateless so every request could go to any instance of the service and expect the same result. This means each service instance must have knowledge of the entire world as opposed to using partitioning. We generated a deterministic polling schedule so the geofences data from different service instances is kept in sync. Thus, this service has a very simple architecture. Background jobs periodically poll geofences data from various datastores. In turn, this data is saved in main memory to serve queries and serialized to the local file system for fast bootstrap on service restarts:
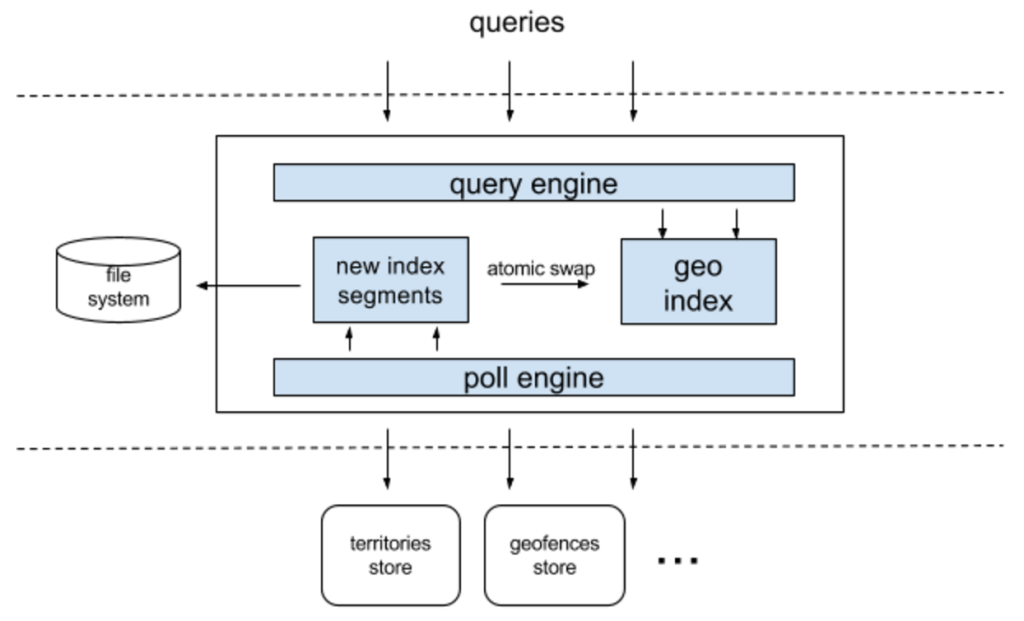 Our service architecture for geofence lookups.
Our service architecture for geofence lookups.
Dealing with the Go Memory Model
Our architecture requires concurrent read/write access to our in-memory geo index. In particular, the background polling jobs write to the index while the foreground query engine reads from the index. For people coming from the single-threaded Node.js world, the Go memory model could present a challenge. While the idiomatic Go way is to synchronize concurrent read/write with goroutines and channels, we were concerned about the negative performance implications. We tried to manage the memory barriers ourselves using the StorePointer/LoadPointer primitives from the sync/atomic package, but that led to brittle and hard-to-maintain code.
Eventually, we settled on the middle ground, using a read-write lock to synchronize access to the geo index. To minimize the lock contention, new index segments were built on the side before being atomically swapped into the main index for serving queries. This use of locks resulted in slightly increased query latency compared to the StorePointer/LoadPointer approach, but we believe the gain in simplicity and maintainability of the codebase was well worth the small performance cost.
Our Experience
Looking back, we are extremely happy with our decision to Go for it and write our service in a new language. The highlights:
- High developer productivity. Go typically takes just a few days for a C++, Java or Node.js developer to learn, and the code is easy to maintain. (Thanks to static typing, no more guessing and unpleasant surprises).
- High performance in throughput and latency. In our main data center serving non-China traffic alone, this service handled a peak load of 170k QPS with 40 machines running at 35% CPU usage on NYE 2015. The response time was < 5 ms at 95th percentile, and < 50 ms at the 99th percentile.
- Super reliable. This service has had 99.99% uptime since inception. The only downtime was caused by beginner programming errors and a file descriptor leak bug in a third party library. Importantly, we haven’t seen any issues with Go’s runtime.
Where Do We Go From Here?
While historically Uber has been mostly a Node.js and Python shop, the Go language is becoming the language of choice for building many of Uber Engineering’s new services. There is a lot of momentum behind Go at Uber, so if you’re passionate about Go as an expert or a beginner, we are hiring Go developers. Oh, the places you’ll Go!